Claude 1위에서 5위로 — 한 달 만에 뒤집어진 AI 모델 순위표

2월에 "지금 가장 좋은 AI 모델이 뭐예요?"라고 물으면 대부분 같은 답을 했어요. Claude가 글 잘 쓰고, GPT가 코딩에 강하고, Gemini가 빠르다고요. 한 달 지나니까 판이 뒤집혀 있더라고요.
Gemini 3.1 Pro가 Chatbot Arena 1505 Elo로 1위. xAI의 Grok 4.20이 1496으로 3위. 한 달 전까지 부동의 1위였던 Claude Opus 4.6이 기본 모드에서 1490으로 5위까지 밀려났어요. GPT-5.4는 6위. "OpenAI 신모델은 곧 1위"라는 공식이 더 이상 안 통하는 시대.
Google의 자신감 — Gemini 3 Pro를 한 달 만에 단종
Google 행보가 인상적이었어요. 2월에 Gemini 3 Pro를 내놓고, 한 달도 안 돼서 3.1 Pro로 교체하더니 3 Pro를 아예 조기 종료시켰어요. 복잡한 추론에서 전작 대비 두 배 이상 성능 향상. GPQA Diamond에서 높은 점수를 찍었어요.
근데 완전히 안착한 건 아니에요. 초기에 503 에러가 빈번했고, 지연 시간이 104초까지 치솟는 사례도 보고됐어요. 프로덕션에 바로 투입하기엔 조심스러운 단계. (프리뷰니까 감수할 부분이긴 한데, 104초는 좀 심하잖아요.)
Grok 4.20 — 에이전트 4개가 팀을 이루는 독특한 구조
일론 머스크의 xAI도 독특한 카드를 내놨어요. Grok 4.20 Beta는 4개의 전문 에이전트가 팀으로 작동해요. Grok이 총괄 조율, Harper가 리서치와 팩트체크, Benjamin이 수학.코딩, Lucas가 창작. 하나의 모델로 모든 걸 해결하려는 다른 회사들과는 다른 접근이에요. 역할을 나눈 팀 구조가 효과를 보고 있는 셈이죠.
GPT-5.4는 '추론 강도 조절'이 눈에 띄어요. API에서 reasoning_effort를 none부터 xhigh까지 5단계로 설정할 수 있거든요. 간단한 분류에는 추론을 꺼서 빠르고 싸게, 복잡한 코드 리뷰에는 최대로. 하나의 모델 안에서 상황에 맞게 조절하는 시대가 된 거예요.
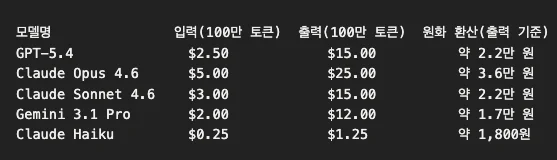
비용까지 따지면 Gemini가 압도적
성능만큼 중요한 게 가격이에요. Arena 1위인 Gemini 3.1 Pro가 출력 100만 토큰당 12달러로 가장 저렴해요. Claude Opus 4.6이 25달러, GPT-5.4가 15달러. 1위가 가격까지 가장 싸다니, 이건 좀 반칙 아닌가요.
코딩은 여전히 Claude가 가장 강해요. SWE-bench Verified에서 약 81%로 GPT-5.4의 59%와 격차가 크거든요. 근데 Arena 순위에서 밀렸다는 건, 범용성에서 더 이상 독보적이지 않다는 신호예요.
오픈소스의 반란 — 격차가 빠르게 좁혀진다
가장 의외였던 건 중국발 오픈소스 모델이에요. GLM-5가 1452 Elo, Kimi K2.5 Thinking이 1451 Elo. 절대 점수로 보면 상위 폐쇄형 모델과 50점 차이인데, 반년 전엔 100점 이상이었거든요. "비싼 API를 써야만 좋은 결과가 나온다"는 전제가 흔들리기 시작한 거예요.
모델 교체 주기도 한 달 단위로 줄었어요. OpenAI는 GPT-5.1을 퇴역시켰고, Google은 Gemini 3 Pro를 한 달 만에 단종시켰어요. 특정 모델에 의존하는 서비스라면 마이그레이션 계획을 항상 염두에 둬야 하는 시대. 다음 달에 이 순위가 또 어떻게 바뀔지, 솔직히 예측이 안 돼요.