초당 2,000건에서 18,000건으로 — IoT 이벤트 파이프라인을 4.2배 빠르게 만든 기록
초당 2,000건에서 18,000건으로 -- IoT 이벤트 파이프라인을 4.2배 빠르게 만든 기록
화재 감지 알림이 3초 늦게 오면 어떻게 될까요? IoT 서비스에서 이벤트 지연은 UI가 느려지는 정도의 문제가 아니에요. 사용자 안전과 직결돼요. 이 글의 저자는 삼성 SmartThings, LG ThinQ, Naver Clova, KT, Kakao 등 국내 주요 IoT 플랫폼과 연동하는 서비스의 백엔드 개발자인데요. 기기 상태 변화를 수신해서 연동된 플랫폼으로 전달하는 중간 다리 역할을 하는 이벤트 파이프라인을 맡고 있어요.
문제는 서비스가 성장하면서 생겼어요. 2년 전까지만 해도 초당 2,000건이었던 기기 이벤트가, 지금은 초당 6,000건을 훌쩍 넘거든요. 기존 인프라와 로직으로는 늘어난 유입량을 못 따라갔고, 금방 지연과 유실로 이어졌어요.
파티션별 순차 처리의 함정 — 기기별로 묶으니 4.2배가 됐다
이벤트 수가 꾸준히 늘었지만, 파티션 수를 유연하게 늘리기 어려웠어요. CPU 성능이 중요해서 인프라 비용이 많이 나가는데, 컨슈머를 마구 늘릴 수도 없는 노릇이고요. 처리 순서도 중요했어요. 단순 병렬 처리는 답이 아니었거든요.
근데 생각해 보면, 한 파티션에 수많은 기기의 이벤트가 섞여 들어오잖아요. 기기 A의 이벤트 순서만 보장되면 되는 건데, 파티션 전체를 순차 처리하고 있었던 거예요. 비효율 포인트.
배치 수신한 이벤트를 기기 ID로 묶고, 같은 기기 이벤트끼리는 순차 처리, 서로 다른 기기 이벤트끼리는 병렬 처리하도록 바꿨어요. '파티션 단위의 단일 스레드 순차 처리 모델에서 벗어나, 애플리케이션 레벨에서의 병렬 처리를 구현한 것' -- 저자가 LLM한테 표현을 맡겼다고 솔직하게 말하더라고요. (웃겼어요.)
결과. 초당 처리량 4,200개에서 18,000개. 4.2배. 대신 새로운 문제가 생겼어요. 그렇게 늘어난 처리량을 기존 리소스로 버틸 수 있느냐는 것. 단순히 비용 들여서 스케일 아웃하면 언젠가 다시 만날 근본적인 문제를 미루는 것뿐이잖아요.
86ms를 2ms로 — 캐시 하나로 87.2%를 깎았다
처리량은 올랐는데, 정작 이벤트 단건의 처리 시간은 늘었어요. 동시 처리가 늘어나니까 DB 커넥션 풀(CP)이 부족해진 거예요. 들쭉날쭉한 쿼리 시간과 CP Pending 수를 모니터링하면서 확인했죠.
쿼리와 인덱스를 점검해서 2ms 이상 걸리는 쿼리를 전부 없앴어요. 빈도는 줄었지만, 그래도 커넥션 부족을 완전히 피할 순 없었어요.
그래서 캐시를 도입했어요. 일부 기기 이벤트는 처리를 위해 다른 서비스와의 통신이 필요했거든요. 응답 시간만큼 블로킹이 발생하고, 외부 서비스 상태에 직접 의존되는 구조. DB 쿼리와 API 요청 데이터를 캐싱하기 시작했어요.
캐시 전략이 꽤 세밀해요.
- Look Aside로 캐시 먼저 조회 후 DB 확인
- 데이터 변경 시엔 Evict Only -- 캐시 업데이트 없이 무효화만
- 트랜잭션 커밋 후 캐시 업데이트는 @TransactionalEventListener로 강제
- 읽지 않을 가능성이 높은 데이터를 미리 캐싱하느라 레디스 시간과 공간을 뺏고 싶지 않았다는 거예요
캐시가 잘못 적용되면 오히려 직접 요청하는 것보다 비효율적이에요. (많은 사람들이 "캐시 = 무조건 빠르다"고 생각하는데, 실제로는 아니거든요.) 테스트해 보니 히트율이 약 60%일 때 캐시를 적용하지 않았을 때와 같은 처리량을 가졌어요. 손익분기점이 60%인 셈이죠.
실제 운영에선? DB 쿼리에서 90%, API 요청에선 95% 이상의 히트율. 이벤트 단건 평균 처리 시간이 86ms에서 2ms로 떨어졌어요. 87.2% 감소. DB와 네트워크 커넥션 사용도 줄어서 커넥션 풀 부족 문제까지 해결됐고요.
배치 삽입으로 DB CPU를 구하고, 백프레셔로 OOM을 막았다
센서 기기의 이벤트는 DB에 저장해서 특정 기간 동안의 상태 이력 조회에 쓰여요. 처리량이 올라가니까 이 데이터 삽입에서도 병목이 생겼어요.
처음엔 Reactive MongoDB를 도입해서 논블로킹 삽입으로 처리량을 개선했어요. 대신 DB CPU 사용률이 올라가서, 인스턴스 타입을 늘려야 하는 경계에 도달했죠. 그래서 배치 삽입으로 갈아탔어요.
DB에 저장할 이벤트를 즉시 삽입하지 않고 Thread-safe한 큐에 모아요. 일정 시간 간격으로 큐를 비우면서 배치 사이즈만큼씩 bulk insert. 배치 삽입이 실패하면 재시도가 아니라 DLT(Dead Letter Topic)로 전달했어요. 빠른 재시도의 실시간성보다, 유실에 안전하게 "언젠가는 기록됨"이 더 중요한 서비스니까요.
결과. 단순 DB 삽입 기준 초당 3,500건에서 20,000건으로 4배 이상 개선. Reactive 방식에서 문제였던 DB CPU 사용률도 안정화됐어요.
매 정각마다 스케줄링으로 인한 이벤트 급증이 발생하는데, 일시적인 몰림에 맞춰 리소스를 급히 늘리면 과부하와 서비스 장애로 이어질 수 있어요. 그래서 카프카 메시지 수신 스레드 풀과 별개로, 메시지 처리용 워커 스레드 풀을 따로 구성했어요.
스레드 수를 미리 고정해서 리소스 과부하를 막고, 스레드 풀의 대기열을 버퍼로 써서 처리 못한 메시지를 임시 보관했어요. 대기열 사이즈를 지정하지 않으면 태스크가 쌓여서 OOM. 가득 차면 메시지 수신 스레드에서 직접 처리하면서, 공간이 생길 때까지 다음 메시지 수신을 대기하게 했어요. 백프레셔.
250ms가 임계점이었다 — WireMock으로 찾아낸 서킷 브레이커 기준
캐시 서버에 예외가 발생하면 DB를 직접 호출하되, 반영 못한 dirty 데이터는 따로 큐에 보관해요. 복구 시 캐시 무효화를 처리할 수 있도록. 일정 개수 이상 쌓이면 관련 캐시 엔트리 전체를 제거하는 방식이에요. 서버 종료 시에도 Graceful shutdown으로 큐에 남은 데이터가 유실되지 않도록 반복 시도하고요.
API 호출과 레디스 장애 상황에선 호출 자체가 비용이에요. 느린 응답의 반복은 전체 처리 지연으로 이어지거든요. 서킷 브레이커를 적용해서 장애 지속을 판단하고 일정 시간 접근 시도를 피했어요.
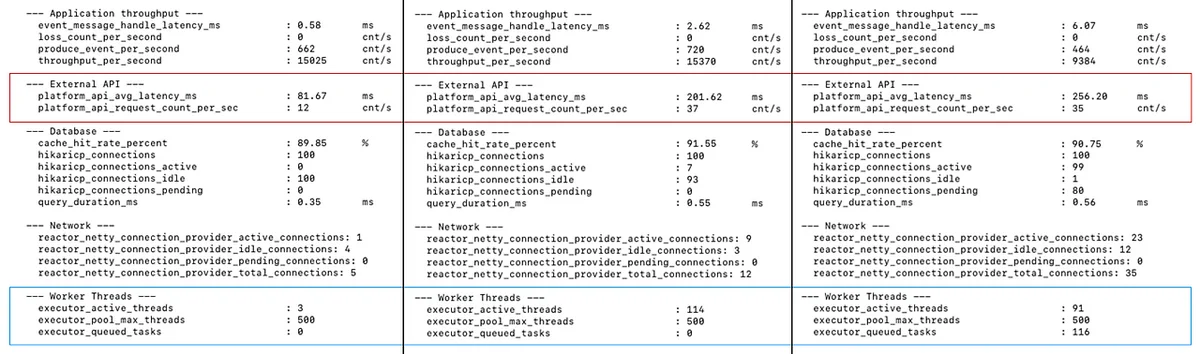
근데 서킷 브레이커의 "재난 기준"은 어떻게 잡았을까요? 외부 서비스를 WireMock으로 대체해서 응답 속도에 따른 리소스 변화를 직접 테스트했어요. Prometheus에 직접 요청해서 실시간 값을 반영하는 커스텀 대시보드도 만들었고요. 그라파나가 전체 상태 확인용이라면, 이건 원하는 매트릭만 골라 값 변화를 명확하게 보는 용도.
동일한 DB 커넥션 풀, 네트워크 커넥션 풀, 워커 스레드 풀 설정에서 외부 API 속도만 바꿔봤어요. 200ms까지는 단건 처리 시간이 약간 늘긴 했지만 처리량이 줄거나 대기가 발생하진 않았어요. 250ms에서 워커 스레드 풀 대기(버퍼링)가 발생하면서 단건 처리 시간이 급증하고, 처리량이 급격히 떨어졌어요. 250ms가 임계점. 이 지표가 리소스 조정과 서킷 브레이커 기준을 설정하는 근거가 됐어요.
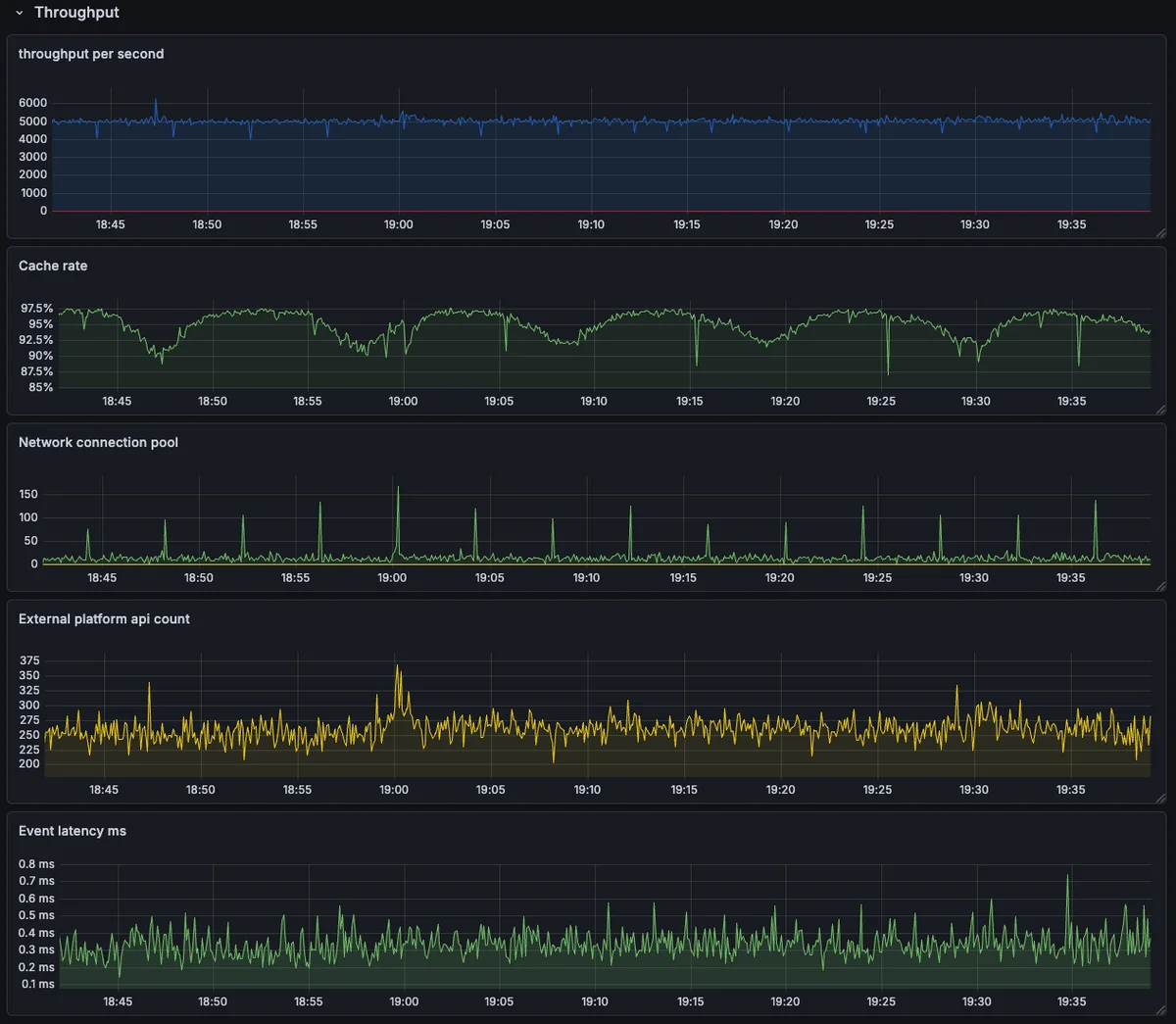
모니터링 대시보드도 재구성했어요. 처리량, 유실률, 캐시 히트율, API 요청·응답 시간, 이벤트 단건 처리 시간까지. OpenTelemetry + Jaeger로 APM을 구성했지만, 이벤트 양이 워낙 많아 샘플링 비율이 극히 적었다고 해요. 단건의 구간별 병목보다는 전체 이벤트 처리 중 발생하는 리소스 변화와 '튐'을 보는 게 더 좋은 지표가 됐고요.
이 데이터들이 단순히 '애플리케이션이 정상'을 넘어, 다음 개선 포인트를 확인하는 배경이 됐어요. '해당 시간대엔 몇 건의 유실이 발생했고, 평균 N ms로 처리되었다'를 보이는 외부 플랫폼과의 소통을 위한 증적으로도 쓰이고요.
4,200에서 18,000. 86ms에서 2ms. 3,500에서 20,000. 숫자만 보면 깔끔한 성공 스토리 같지만, 각 단계마다 새로운 병목이 튀어나왔다는 게 이 글의 진짜 포인트예요. 처리량을 올리면 커넥션이 부족해지고, 캐시를 넣으면 장애 대응을 고민해야 하고, 배치를 넣으면 실패 처리를 설계해야 하고. 결국 비용을 들여 스케일 아웃하면 넘길 수 있는 문제들을, 근본적으로 풀겠다고 한 것. 그게 어려운 거잖아요.