GS SHOP은 왜 영상을 '보지 못한 채' 추천하고 있었을까
GS SHOP의 숏픽 추천은 영상 추천이 아니었어요. 정확히 말하면, 영상을 "이해하지 않은 채" 영상을 노출하고 있었어요. 상품과 상품 사이의 추천이 먼저 일어나고, 추천된 상품에 숏폼 영상이 있으면 그 영상이 따라 나오는 방식이었거든요.
영상의 내용은 전혀 반영되지 않았어요. 이유는 하나. 영상을 이해할 수단이 없었으니까요.
이 팀이 멀티모달 모델을 붙여서 영상을 데이터로 바꾸는 과정이 꽤 흥미로워요.
PD의 고충에서 시작된 질문
이 여정의 출발은 추천 시스템이 아니라 영상 검색이었어요.
GS SHOP에서는 매일 생방송 이후에 PD가 수십 개의 영상을 하나씩 재생하며 필요한 장면을 수동으로 찾아야 했어요. "이 영상에서 쇼핑호스트가 시식하는 장면이 어디였더라..." 그 장면 하나를 찾는 데 몇 시간이 걸리기도 했대요.
여기서 자연스럽게 질문이 떠올랐어요. "영상도 텍스트처럼 검색할 수 있지 않을까?"
영상 이해 모델을 찾던 중 TwelveLabs를 알게 됐고, 그 중 Marengo라는 모델을 접목해 영상 검색 대시보드를 바로 만들었어요.
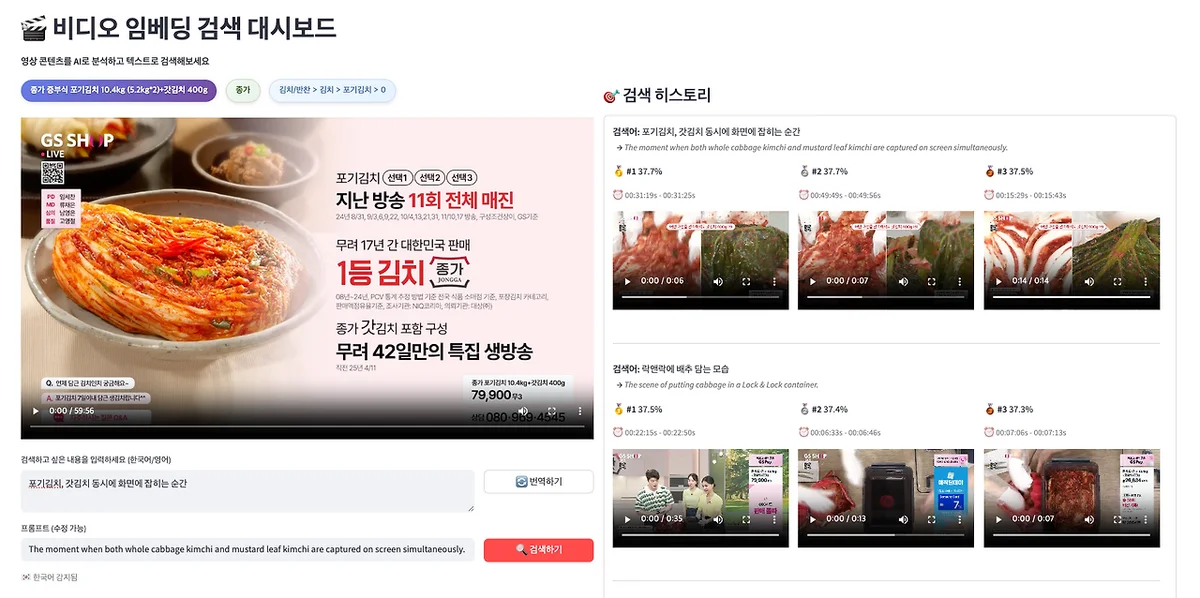
몇 시간 걸리던 장면 검색이 몇 초 만에 해결되는 가능성을 본 거예요. 근데 조사하면서 흥미로운 걸 발견했어요. TwelveLabs는 두 개의 모델을 지원하더라고요.
| 모델 | 역할 | 질문 방식 | |------|------|-----------| | Marengo | 영상 장면 검색 | "이 장면이 몇 초에 있나?" | | Pegasus | 영상 전체 질의/응답 | "이 영상이 무엇에 관한 건가?" |
PD 업무에는 Marengo가 맞았지만, Pegasus는 검색 그 이상의 가능성을 갖고 있었어요. 이미 영상을 이해하고 있었거든요.
영상은 이미지에 시간이 더해진 데이터다
이 시점에서 숏픽 추천이 어떻게 작동하는지 다시 뜯어봤어요.
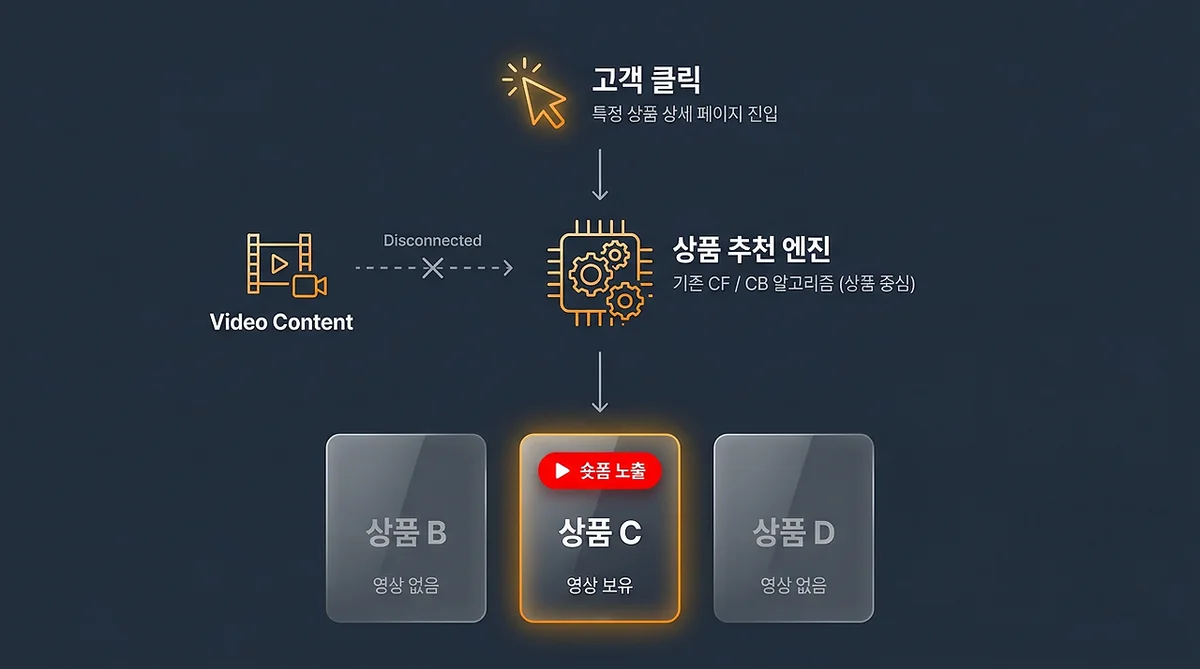
카테고리, 브랜드, 상품명, 이미지 — 시스템이 다룰 수 있는 건 전부 멈춰있는 데이터였어요. 영상을 이해할 수단이 없었기 때문에 상품 정보에 기댈 수밖에 없었던 거예요.
그렇다면 영상은 뭘까요?

영상은 상품 이미지에 시간축이 더해진 형태예요. 정보의 밀도가 근본적으로 달라요. 사람이 영상을 보면서 직관적으로 받아들이는 맥락 — "아 이 제품 실제로 효과가 있나 보다", "저 MC가 이렇게 좋아하는 걸 보면 진짜인가 봐" — 이런 정보들은 기존 시스템이 전혀 건드리지 못하는 영역이었어요.
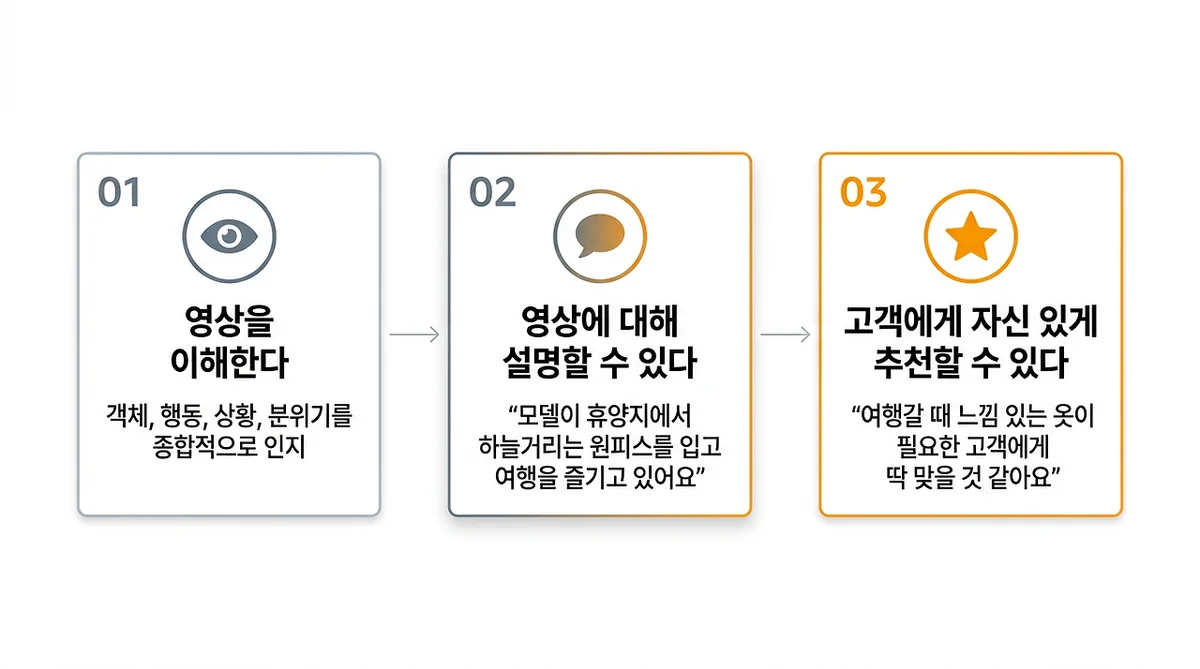
이해한다는 건 자신 있게 누군가에게 설명할 수 있다는 것이고, 이건 추천의 본질이기도 해요. "이게 당신에게 맞을 것 같아"라고 말하려면, 먼저 그게 뭔지 알아야 하잖아요.
멀티모달 모델이 시간의 흐름을 읽기 시작했다
영상 기반 추천은 오래된 숙제였어요. Part 1에서 To-Be로 적어놓긴 했지만 당장 실현 가능하다고 생각하진 않았대요. 영상에서 의미 있는 정보를 기계가 꺼낼 수 있는지 자체가 불분명했으니까요.
근데 2024년을 지나면서 분위기가 바뀌었어요.
LLM이 텍스트를 넘어 이미지를, 이미지를 넘어 영상을 이해하기 시작한 거예요. 멀티모달 모델들이 빠르게 등장했고, 몇 가지 시도를 해 보면서 "이 수준이면 실제 서비스에 붙일 수 있겠다"는 감이 왔대요. 타이밍이 맞아 떨어졌어요.
GS SHOP에는 매일 생방송이 쌓이고, 숏폼 콘텐츠가 쌓이고, S3에 저장되는 영상들이 있었어요. 똑똑해진 모델의 입력 시퀀스가 늘어나면서 비로소 기계가 이 시간의 흐름을 이해할 수 있게 된 거예요. 드디어 사람이 바라보는 세상과 기계가 바라보는 세상의 차원이 일치하게 됐다는 말이 과장이 아니었어요.
AWS 안에서 다 닫히는 파이프라인
Pegasus를 숏픽에 적용하려는 순간, 인프라 고민이 생각보다 크지 않았대요. 이미 모든 재료가 AWS 위에 있었거든요. 영상은 S3에, 상품/방송 정보는 Redshift에, 그리고 Pegasus는 AWS Bedrock에 올라가 있었어요. 퍼즐 조각들이 같은 판 위에 놓여 있었던 셈이죠.
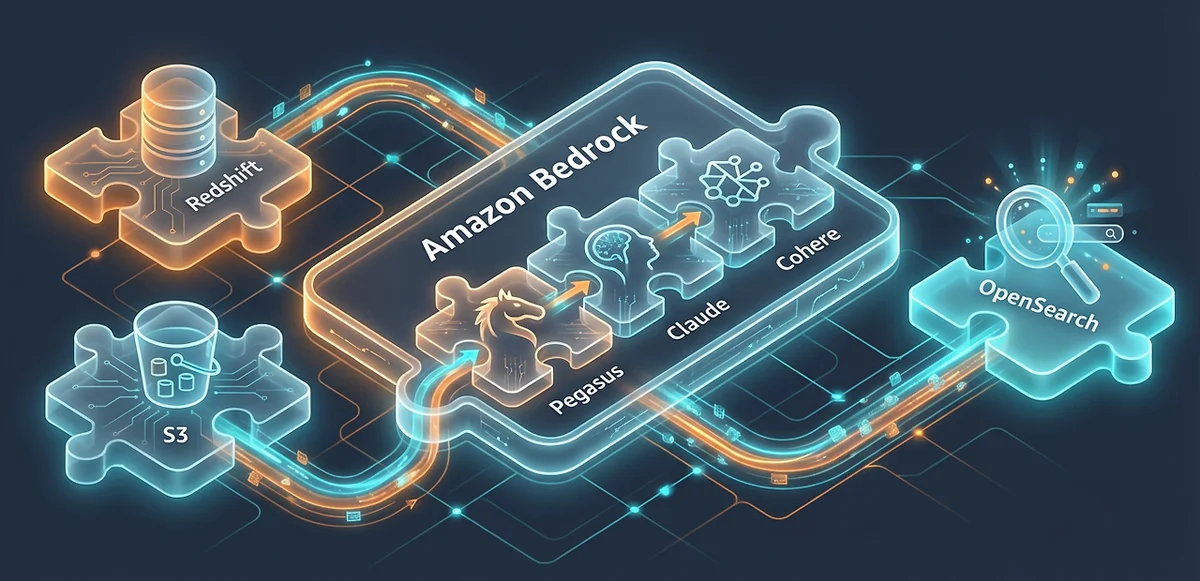
각 단계가 하는 일은 명확해요.
Pegasus는 영상을 보고 한국어로 장면을 설명해요. "쇼핑호스트가 클렌징폼을 직접 얼굴에 올려 풍성한 거품을 만들며 피지 개선 효과를 강조하고 있다" 같은 문장을 만들어내는 거예요. Claude는 그 설명에서 추천에 쓸 수 있는 핵심 키워드를 뽑아내요. "체험형 시연", "피지 개선", "거품 풍부", "셀럽 인증" 같은 소구 포인트죠.
Cohere는 이 텍스트를 벡터(숫자 배열)로 변환해요. 비슷한 맥락의 영상은 벡터 공간에서 가깝게 위치하게 돼서, "이 영상과 비슷한 영상"을 수학적으로 계산할 수 있게 돼요. OpenSearch가 이 벡터들을 인덱싱해서 실시간 추천 서빙에 쓰고요.
영상이 S3에 올라가는 시점부터 추천 후보에 등록되기까지, 이 모든 과정이 AWS 안에서 닫혀요. 별도 인프라를 구축할 필요가 없었고, 기존 서비스에 새로운 레이어를 자연스럽게 얹을 수 있었대요.
솔직히 이 부분은 좀 운이 좋았다고 봐요. (처음부터 설계된 것처럼 맞아 떨어졌다는 건 팀의 겸손이고, 실제로는 AWS 생태계 안에 이미 필요한 조각이 다 있었던 거니까요.)
이제 영상을 이해할 수 있게 됐어요. 다음 질문은 하나예요 — "이해한 영상을, 어떻게 추천으로 연결할까?" 그 이야기는 Part 3에서 이어진대요.