CPU 사용률 50%를 5%로 — 채널톡이 화상회의 배경 블러를 GPU로 옮긴 이야기

"회의 중인데, 뒤에 빨래가 걸려있어요..." 재택근무가 일상이 되면서 화상회의 배경 블러는 거의 필수 기능이 됐잖아요. 채널톡의 Meet 서비스에도 배경 블러 기능이 이미 출시되어 있었어요. 근데 문제가 있었습니다.
"저사양 노트북에서는 너무 느려요." "배경 블러를 켜면 화면이 끊겨요." "노트북이 뜨거워지고 팬이 시끄러워요."
측정해보니 심각했어요. CPU 사용률 50~60%. 배경 블러 하나가 CPU의 절반 이상을 먹고 있었습니다. 저사양 기기에서는 화면이 버벅거리고 마우스도 느려졌고요. 대체 왜 이렇게 느렸을까?
207만 픽셀을 싱글 스레드가 혼자 돌린다
초기 구현을 들여다보면 이해가 돼요. 배경 블러를 구현하려면 먼저 사람과 배경을 분리해야 하는데, 이를 위해 Google의 MediaPipe Selfie Segmentation 모델을 썼어요. 브라우저에서도 돌아가고, 성능도 괜찮은 녀석이죠.
초기 파이프라인은 이랬습니다. 비디오 프레임 캡처 → MediaPipe 세그멘테이션 → 신뢰도 마스크 생성 → CPU에서 픽셀 순회하며 ImageData 업데이트 → Canvas에 합성 및 블러 적용 → 최종 프레임 출력.
MediaPipe가 반환하는 신뢰도 마스크는 각 픽셀이 사람일 확률을 0~1 사이 값으로 표현해요. 얼굴 중앙은 0.99, 머리카락 경계는 0.7, 배경은 0.1 이런 식이죠.

문제는 이 마스크 데이터를 어떻게 활용하느냐였어요. 가장 직관적인 방법 — JavaScript로 모든 픽셀을 순회하며 ImageData를 업데이트하는 것. Google이 제공하는 MediaPipe 공식 가이드 코드에서도 동일한 방식을 쓰고 있었거든요.
```javascript for (let i = 0; i < maskData.length; i++) { const confidence = maskData[i]; updateImageDataPixel(imageData, i, confidence * 255); } ```
코드는 단순하고 명확했어요. 로컬 테스트에서도 잘 돌아가는 것처럼 보였고요. 그런데 실제 화상회의 환경에서 돌려보니 문제가 드러났습니다.
1920x1080 해상도. 2,073,600 픽셀. JavaScript 싱글 스레드가 이 모든 픽셀을 하나씩 순차 처리하고 있었어요. 각 픽셀마다 4개 채널(RGBA)을 처리하니까, 한 프레임에 800만 번 이상의 배열 접근이 발생합니다. 30fps를 목표로 하면? 초당 약 2억 4천만 번.
잘못된 도구를 쓰고 있었던 거예요. 픽셀 처리는 본질적으로 병렬 처리에 이상적인 작업이거든요. 각 픽셀의 처리가 독립적이고, 모든 픽셀에 동일한 연산을 적용하고, 데이터 의존성이 없으니까. 이론적으로는 207만 개 픽셀을 동시에 처리할 수 있어요. 하지만 JavaScript 싱글 스레드에서는 불가능했죠.
WebGL 쉐이더 4줄이 for 루프를 대체했다
브라우저에서 GPU를 활용하는 방법. WebGL. OpenGL ES 2.0 기반이고, 모든 현대 브라우저에서 지원하고, 플러그인 없이 동작해요.
근데 WebGL을 선택한 결정적 이유는 따로 있었어요. MediaPipe가 WebGL 텍스처를 직접 지원한다는 것. MediaPipe의 세그멘테이션 결과는 GPU 메모리에 WebGL 텍스처로 저장되는데, `mask.getAsWebGLTexture()` 메서드를 통해 이 텍스처를 직접 접근할 수 있거든요. CPU로 데이터를 복사할 필요 없이, GPU 메모리에서 바로 처리 가능. 이게 핵심이었습니다.
핵심 아이디어는 간단해요. CPU에서 하던 픽셀 순회를 GPU 쉐이더로 대체하자.
```glsl // GPU 방식 (병렬 처리) void main() { float a = texture2D(textureSampler, texCoords).r; gl_FragColor = vec4(a, a, a, a); } ```
4줄. 이 4줄이 207만 픽셀에 대해 동시에 실행돼요. `main()` 함수가 207만 번 순차 실행되는 게 아니라, 207만 개 픽셀에 대해 한꺼번에 실행됩니다.
아키텍처가 바뀌면 데이터 흐름이 바뀐다
변경 전 파이프라인의 문제를 정확히 짚으면 이래요. MediaPipe는 GPU에서 실행되어 GPU 메모리에 마스크를 생성하는데, 이걸 CPU로 가져와서 처리하고, 다시 Canvas 렌더링을 위해 GPU로 보내야 했어요.

불필요한 CPU-GPU 전송과 느린 CPU 처리. 이중 병목이었습니다.
변경 후에는 모든 처리가 GPU 내에서 이루어져요.
1. 비디오 프레임 캡처 2. MediaPipe 세그멘테이션 실행 (GPU) 3. 신뢰도 마스크를 WebGL Texture로 직접 접근 4. WebGL 쉐이더로 마스크 변환 (GPU, 2ms 안에 완료) 5. ImageBitmap으로 변환 6. Canvas 2D에 합성 + 블러 적용 7. 최종 프레임 출력

CPU를 거치지 않으니까 데이터 전송 오버헤드가 사라지고 CPU 사용률이 대폭 줄었어요.
모든 걸 WebGL로 다시 만들지는 않았다
여기서 중요한 건, 모든 것을 WebGL로 재구현하지 않았다는 점이에요. 블러 효과를 쉐이더로 만들고, 이미지 합성도 쉐이더로 만들면 코드가 복잡해지고, 개발 시간이 길어지고, 디버깅과 유지보수가 어려워지거든요.
실제로는 픽셀 변환만 WebGL로 처리하고, 나머지는 Canvas 2D API를 그대로 썼어요. Canvas 2D도 현대 브라우저에서 GPU 가속을 지원하니까, `globalCompositeOperation`이나 `filter: blur()`는 이미 충분히 빨랐거든요. 문제는 오직 JavaScript 픽셀 순회 부분이었습니다.
Chrome DevTools로 프로파일링한 결과, 픽셀 순회가 전체 처리 시간의 70%를 차지했어요. 명확한 병목. 이 부분만 WebGL로 바꾸는 데 3일 정도 걸렸고, CPU 사용률을 80% 줄였습니다. 나머지를 WebGL로 재구현하면 훨씬 오래 걸리지만 효과는 미미했을 거예요.
병목 구간만 최적화하고, 나머지는 기존 API를 활용했습니다. 실용적이죠.
쉐이더 구현 — 버텍스와 프래그먼트
WebGL에서 그래픽을 그리려면 쉐이더(Shader)라는 GPU 프로그램을 작성해야 해요. 두 종류가 있는데, 버텍스 쉐이더는 정점 처리를 담당하고 프래그먼트 쉐이더는 픽셀 색상 계산을 담당합니다.
버텍스 쉐이더는 화면 전체를 덮는 사각형을 정의해요. WebGL에서는 사각형을 2개의 삼각형(6개 정점)으로 그립니다. 좌표계가 다른 게 함정인데 — WebGL은 좌하단이 원점이고 Y축이 위로 향하는 수학적 좌표계를 쓰고, 이미지는 좌상단이 원점이고 Y축이 아래로 향하거든요. 그래서 `texCoords.y = 1.0 - texCoords.y;` 한 줄로 Y축을 반전시켜야 했어요.
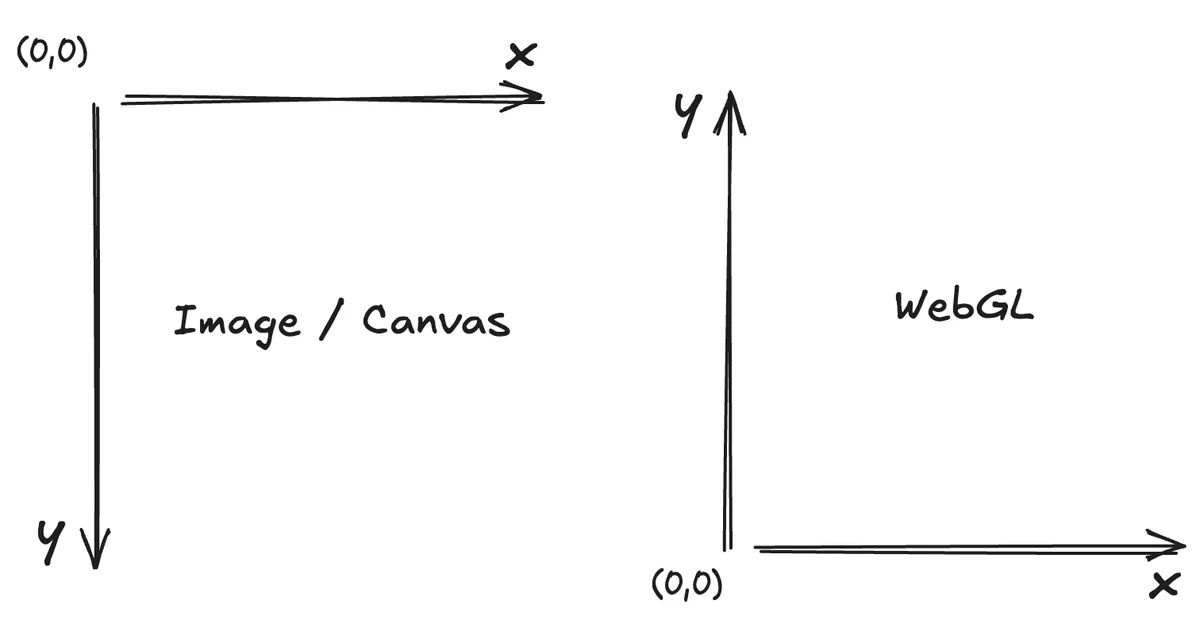
처음 WebGL을 적용했을 때 결과 이미지가 상하 반전되어 나왔다고 해요. OpenGL의 역사적 배경 때문인데, 3D 그래픽에서는 Y축이 위를 향하는 게 자연스럽거든요. (이걸 모르면 꽤 당황스러울 거예요.)
프래그먼트 쉐이더의 핵심 함수는 앞서 본 4줄이에요. `texture2D(textureSampler, texCoords).r`로 마스크 값을 가져오고, RGBA 모두에 같은 값을 적용해서 흑백 이미지를 생성합니다.
실제 변환 함수에서는 `mask.getAsWebGLTexture()`로 GPU 메모리의 텍스처를 직접 가져오고, `gl.drawArrays(gl.TRIANGLES, 0, 6)` 한 줄이 GPU에 "이제 처리해"라고 명령하는 부분이에요. 이 순간 GPU가 수천 개의 코어를 동원해서 207만 픽셀을 동시에 처리합니다.
Canvas 2D에서의 합성 과정은 4단계예요. 마스크만 그리기 → `source-in`으로 인물만 추출 → `blur` 필터 설정 → `destination-atop`으로 배경 합성.

프레임 레이트 제어 — requestAnimationFrame을 안 쓴 이유
비디오 스트림은 보통 30fps 또는 60fps로 들어와요. 근데 매 프레임마다 세그멘테이션을 실행하면 불필요한 부하가 발생하잖아요.
`setInterval`로 30fps(33.3ms 간격)에 고정했어요. `requestAnimationFrame` 대신. `requestAnimationFrame`은 브라우저의 렌더링 사이클에 동기화되어 보통 60fps로 도는데, 비디오 처리는 렌더링과 독립적으로 동작해야 하고, 화상회의에 30fps면 충분하고, 일정한 부하가 배터리 관리에 유리하니까요.
CPU 50~60%에서 5~10%로
결과. CPU 사용률 50~60%에서 5~10%로 떨어졌어요. 10분의 1 수준. JavaScript 픽셀 순회가 사라지면서 메인 스레드가 해방됐고, GPU가 병렬 처리를 담당하면서 CPU는 다른 작업에 집중할 수 있게 됐습니다.
사용자 경험은 체감이 확실했어요. 렉이 완전히 사라졌고, UI가 부드럽게 반응하고, 팬 소음이 줄고, 배터리 걱정이 없어졌고, 다른 앱 동시 사용도 가능해졌습니다.
프론트엔드 개발자에게 GPU는 이미 익숙하다
"WebGL은 너무 어렵지 않나요? 그래픽스 전공이 아니면 못하는 거 아닌가요?"
사실 프론트엔드 개발자에게 GPU는 이미 낯설지 않아요. CSS에서 `transform: translateX(100px)`이나 `opacity: 0.5`가 빠른 이유가 뭔지 아세요? GPU에서 처리되기 때문이에요. `left: 100px`이나 `width: 200px`은 CPU에서 처리되고 리플로우가 발생하는데, transform과 opacity는 GPU 레이어로 분리되어 처리됩니다. 우리는 이미 GPU를 활용하고 있었던 거예요. 명시적으로 제어하지 않았을 뿐이죠.
CSS로 만족스러운 결과를 얻을 수 없을 때 Canvas 2D로 넘어가듯, Canvas 2D로 해결할 수 없을 때 WebGL로 넘어가면 돼요.
이번 작업에서 채널톡 팀이 따른 원칙은 단순했습니다. 측정으로 병목을 찾고, 병목 구간만 최적화하고, 코드 가독성을 유지한다. WebGL, GPU, 쉐이더 프로그래밍이 처음엔 낯설었지만, 결국 문제를 해결하기 위한 도구였을 뿐이라고 해요. CPU 사용률이 높거나 렉이 발생한다면, GPU 활용을 고려해보는 게 답일 수 있습니다.