채널톡이 상용 TTS를 버리고 직접 만든 이유 — 200개 선호쌍으로 슈퍼톤과 GPT4o를 이겼다

상용 TTS는 이미 충분히 많잖아요. 슈퍼톤, 일레븐랩스, GPT4o까지. 근데 채널톡 AI팀은 그걸 버리고 자체 TTS를 만들었어요. 이유가 세 가지라고 하더라고요. 상담사가 말하는 특유의 억양과 리듬(프로소디)이 상용 모델에서는 일관되게 나오지 않는다는 것, 한국어에서 흔한 한영 혼용이나 날짜/시간/주문번호 같은 상식 기반 발화 처리가 취약하다는 것, 그리고 궁극적으로 정말 사람 같은 목소리를 만들고 싶다는 것. A/B 테스트에서 그 세 가지를 전부 달성한 결과가 나왔다는 게, 솔직히 좀 놀라운 얘기예요.
4만 시간을 먹여도 국어책 읽기 수준이었다
오픈소스 TTS 모델은 대부분 영어 기반이에요. 여기에 한국어를 가르치려면 대량의 한국어 데이터가 필요한데, 채널톡은 AIHUB에서 약 3~4만 시간의 한국어 학습 데이터를 수집했어요. (Audio, Text) 쌍으로 이루어진 데이터를 LLaSA-1B 모델에 Continual Pre-training 하는 방식이었고요.
근데 문제가 있었어요. 이렇게 학습한 모델은 화자를 원하는 대로 컨트롤하기 어렵더라고요. 남녀 나이대 정도는 조절 가능한데, 같은 텍스트에 대해서 매번 다른 목소리가 나와요. "20대 여자 상담사"로 프롬프트를 주고 생성하면 어색하진 않은데, 한 번 더 생성하면 전혀 다른 목소리가 나오는 거예요.
AIHUB 데이터의 특성이 문제였어요. 대부분 적어놓은 텍스트를 읽는 식이다 보니 자연스러운 음색이 안 나왔거든요. 결국 돈 문제도 아니고 데이터 양 문제도 아니에요. 데이터의 질. 국어책을 읽는 톤으로는 상담사 말투가 나올 리 없잖아요.
실제 상담 녹음 16시간이 4만 시간을 이겼다
제품에 넣으려면 매번 같은 화자가 일관되게 발화해야 해요. 그래서 채널톡은 방향을 바꿨어요. 텍스트를 주고 읽게 하는 녹음이 아니라, 실제 상담 대화에서 녹음된 상담사 음성을 사용한 거예요.
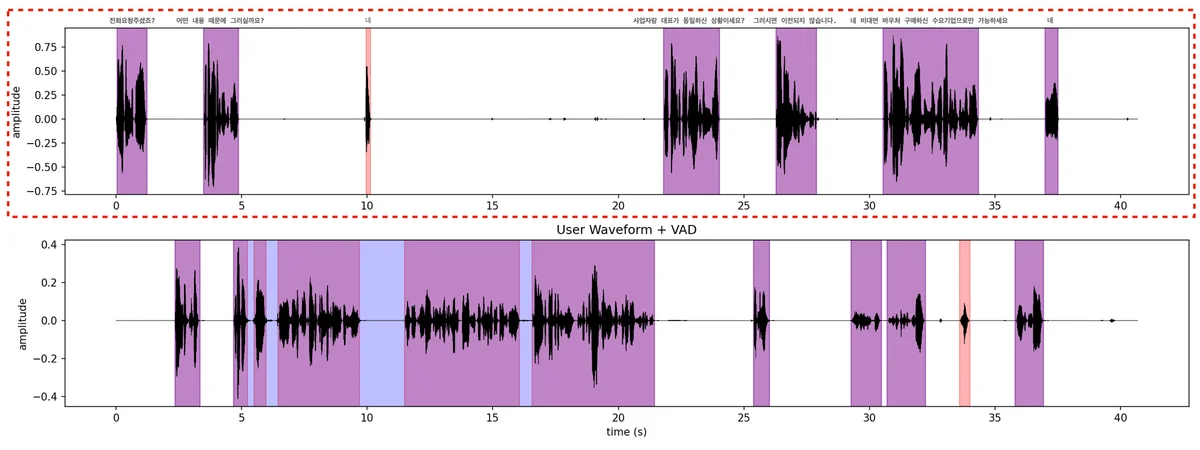
동일 상담사의 내부 발화 데이터 16시간을 활용했어요. (지금 채널톡 전화ALF 서비스에서 '하나'로 활약하고 있다고요.) 실제 상담사-유저 간 대화에서 상담사 채널만 분리하는 speaker segmentation을 수행하고, 분리된 오디오에 whisper-large-v3로 자동 전사 파이프라인을 구성한 거예요.
결과물은 이런 형태의 TTS 훈련 포맷이 돼요:
```json [ (audio_segment_1, "전화요청주셨죠?"), ... (audio_segment_n, "네") ] ```
4만 시간 vs 16시간. 양으로 보면 비교가 안 되죠? 근데 실제 상담사 음성 16시간만 학습해도 훨씬 좋은 프로소디의 발화가 일관적으로 나왔어요. 여담이지만, 이게 ML에서 자주 보는 패턴이에요. 데이터 양보다 도메인 적합성이 결정적인 케이스. 어쨌든 중요한 건 이 16시간이 모델의 톤을 완전히 바꿔놨다는 거예요.
GRPO로 명료도를 올리니까 국어책 톤으로 돌아갔다
Mono-Speaker 파인튜닝 이후에도 문제가 남았어요. 모든 발화가 완벽하지는 않다는 거예요. "안녕하세요"를 넣었는데 "아 안녕하세요"라고 너무 자연스럽게 읽어버린다거나. 상담 상황에서는 명료도가 중요하잖아요.
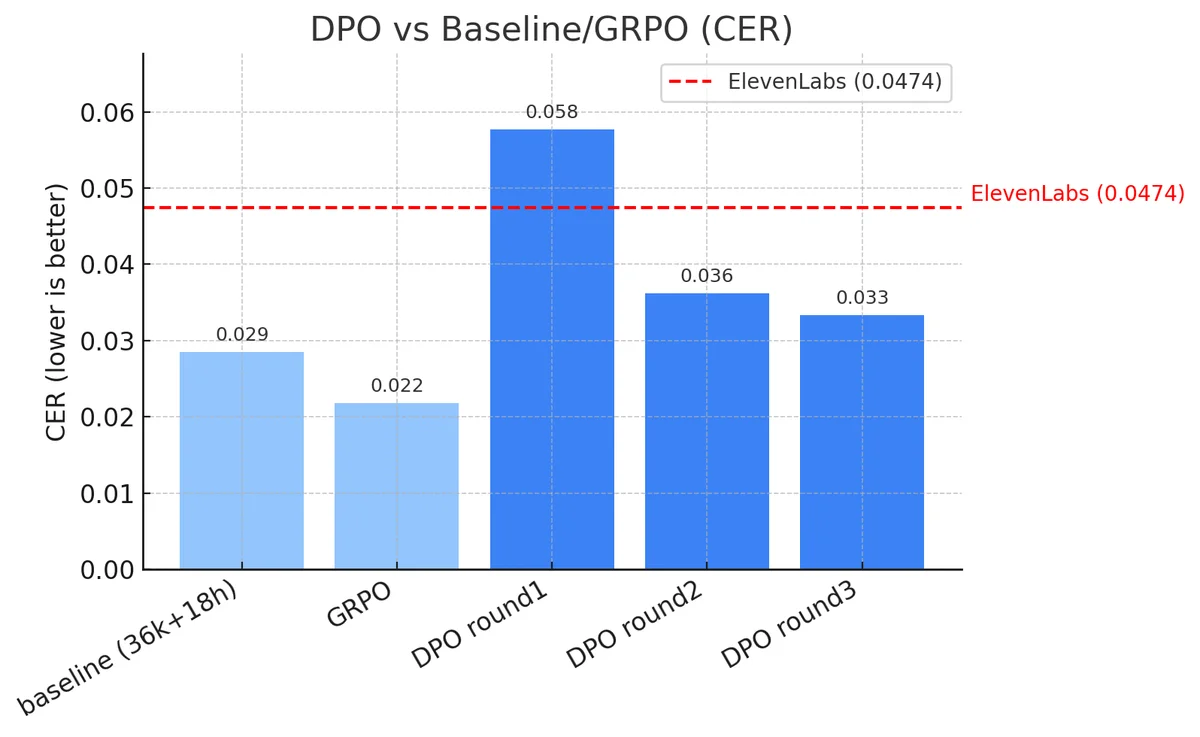
발화 명료도를 올리기 위해 CER(Character Error Rate)을 보상 함수로 쓰는 GRPO(Group Relative Policy Optimization) 강화학습을 적용했어요. CER을 Verifiable Reward로 쓰면 데이터 없이 텍스트만 주어져도 무한히 학습이 가능하거든요. 이 파이프라인은 오픈소스로 공개했고요.
GRPO로 학습했을 때 CER이 가장 낮게 나왔어요. 베이스라인(Mono-Speaker Finetuning)보다 발화 명료도가 확실히 개선된 거예요. 근데 한 가지 문제가 생겼어요. 명료도만 높이다 보니까 발화가 단조로워진 거예요. 마치 국어책 읽는 듯한 monotone. (아니 이게, 명료도를 올리면 자연스러움이 떨어지고, 자연스럽게 하면 명료도가 내려가는 거예요. 트레이드오프가 이렇게 노골적으로 나올 줄이야.)
200개 선호쌍으로 슈퍼톤을 이기다
단조로운 발화와 가끔 발생하는 fallback("안녕하세요"가 "아~~~안녕하세요"로 나오는 것) 문제를 해결하기 위해 DPO(Direct Preference Optimization)를 적용했어요.
방법은 꽤 직관적이에요. 베이스라인 모델에서 같은 입력으로 두 개의 결과를 샘플링하면, 하나는 명료하고 음색이 좋고, 하나는 그렇지 않잖아요. 이걸 (win, lose) 선호쌍으로 수집해서, 모델이 win을 lose보다 높은 확률로 생성하도록 학습시키는 거예요.
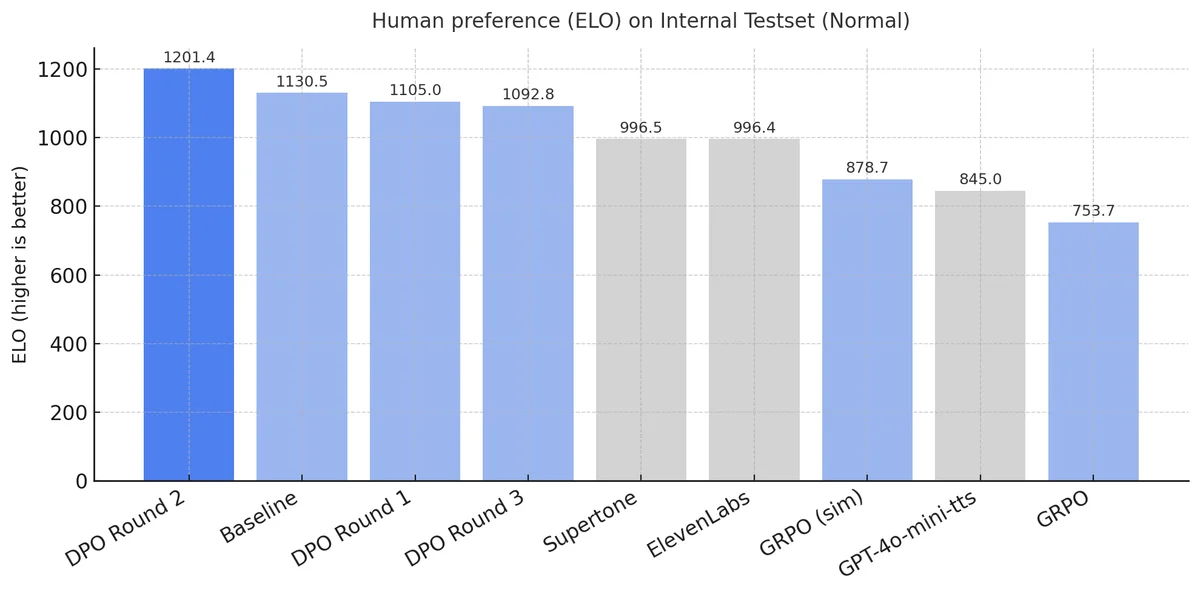
이걸 약 200개 샘플 정도로 반복 학습했는데 — DPO Round 2 모델이 A/B 테스트에서 슈퍼톤, 일레븐랩스, GPT4o를 다 이겼어요. "상담사향에 더 적합하며 사람 같다"는 평가를 받은 거예요. 200개. 수만 개가 아니라 200개예요.
더 자세한 내용은 "No Verifiable Reward for Prosody: Toward Preference-Guided Prosody Learning in TTS"라는 논문에서 확인할 수 있어요.
낭독을 넘어서
채널톡이 Channel-TTS로 다음에 가려는 곳은 conversational TTS예요. higgs-audio, CSM 같은 대화형 TTS와 qwen3-omni가 보여주는 "듣고 이해하고 행동하는" 흐름에 맞춰서, 단순 낭독을 넘어 상황 맥락에 맞게 말하는 모델로 확장하고 있다고 해요.
GRPO로 명료도를, DPO로 상담사향 프로소디를 다듬어서 실제 콜에서 사람 같은 톤과 턴테이킹을 개선 중이라는데 — 결국 이 이야기의 핵심은 단순해요. 4만 시간의 범용 데이터보다 16시간의 도메인 데이터가 낫고, 복잡한 보상 함수보다 200개의 사람 선호가 더 강력하다는 거예요. ML에서 "데이터가 전부"라고들 하지만, 정확히는 "맞는 데이터가 전부"인 셈이죠.