수천만 건이 쌓이면 인덱스로는 안 된다 — 파티셔닝 전략 실전 가이드

데이터가 수천만, 수억 건 쌓이기 시작하면 인덱스를 아무리 잘 설계해도 스캔 비용 자체가 커져요. 백업이나 유지보수 작업도 점점 부담스러워지고요. 이럴 때 가장 먼저 고려하게 되는 게 파티셔닝(Partitioning)이에요.
큰 테이블을 작은 단위로 쪼개서 쿼리는 필요한 조각만 읽고, 운영 부담도 줄이는 거죠. 근데 막상 도입하려고 하면 전략이 너무 많아요. Range, Hash, List, Composite, 수직 파티셔닝... 뭘 써야 하는지 감이 안 잡히는 거예요.
파티션 프루닝이 핵심이다
파티셔닝의 본질부터 짚고 가야 돼요.
파티셔닝은 대용량 테이블이나 인덱스를 더 작고 관리하기 쉬운 단위(파티션)로 분할하는 프로세스예요. 근데 핵심은 데이터를 "예쁘게 보관"하는 게 아니에요. 불필요한 파티션은 생략하고 필요한 파티션만 다루는 것. 이걸 파티션 프루닝(Partition Pruning)이라고 부르고, 이게 파티션 전략을 선택하는 유일한 기준점이에요.
데이터를 삽입하거나 조회할 때, 즉 사용할 때가 중심이 되어야 한다는 거예요. WHERE 절을 기반으로 데이터베이스 쿼리 플래너가 어떤 파티션을 스캔할지 자동으로 결정하는데, 이 프루닝 없이는 모든 파티션을 스캔하게 돼서 파티셔닝의 의미 자체가 사라져요.
파티셔닝 전략은 크게 3가지 축으로 나눌 수 있어요.
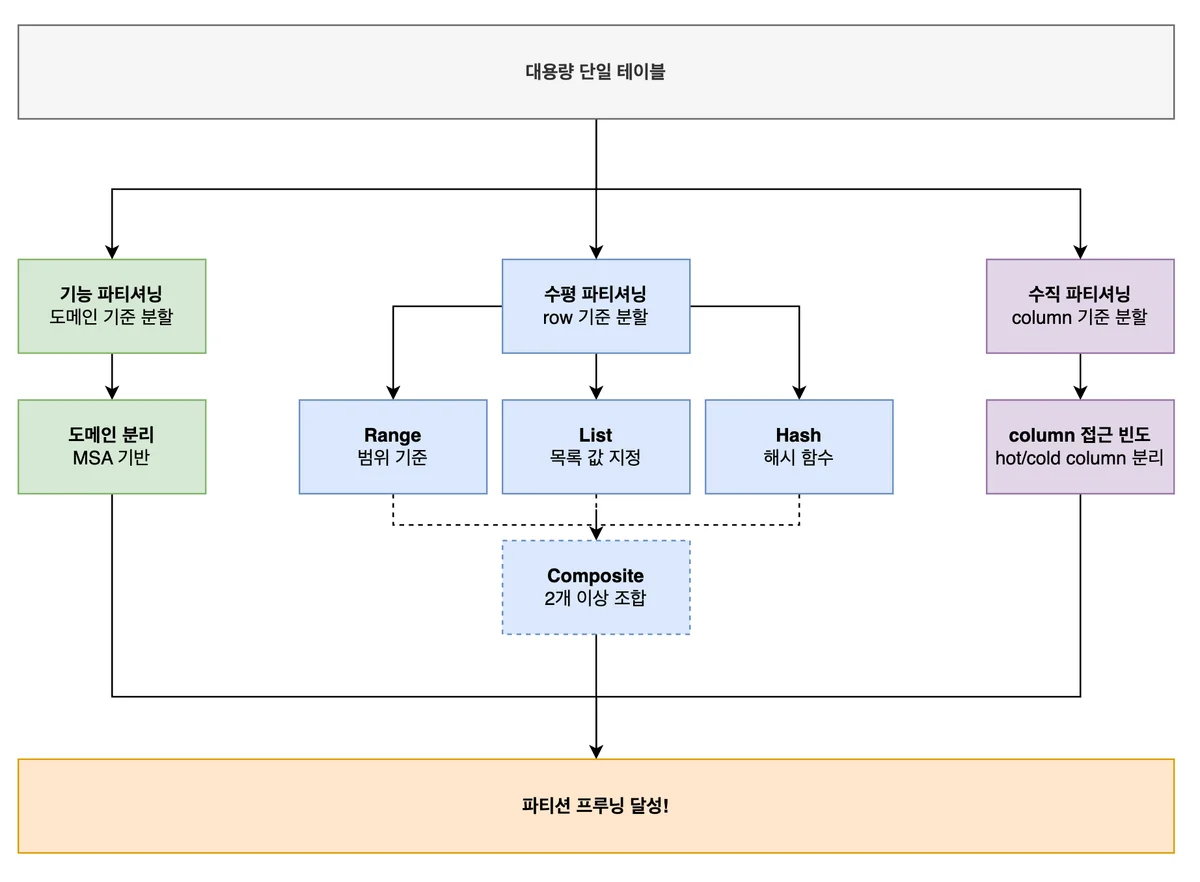
이 그림을 기억해두면 아래 내용이 훨씬 잘 들어올 거예요.
수평 파티셔닝 — 행을 기준으로 쪼갠다
모든 파티션이 동일한 스키마를 유지한 채 행(row) 기준으로 데이터를 나누는 방식이에요. 규모 단위를 데이터베이스로 키우면 샤딩(Sharding)이라고도 부르는데, 샤딩은 여러 DB에 분산된 데이터를 관리해야 하니까 트랜잭션 관리나 JOIN이 복잡해져요. 가능하면 테이블 파티셔닝을 먼저 채택하고 샤딩은 나중에 고려하는 게 맞아요.
범위(Range) 파티셔닝은 날짜나 숫자처럼 구간을 특정 지을 수 있는 컬럼 값의 범위를 기준으로 분할해요. 연도별, 월별, 일별 같은 시계열 데이터가 가장 적합하죠.
```sql CREATE TABLE orders ( order_id BIGINT, order_date TIMESTAMP NOT NULL, ... ) PARTITION BY RANGE (order_date);
CREATE TABLE orders_2025_01 PARTITION OF orders FOR VALUES FROM ('2025-01-01') TO ('2025-02-01'); CREATE TABLE orders_2025_02 PARTITION OF orders FOR VALUES FROM ('2025-02-01') TO ('2025-03-01'); ```
해시(Hash) 파티셔닝은 파티션 키에 해시 함수를 적용해서 파티션 전체에 균일하게 분산시켜요. 시계열 데이터가 없거나 핫 파티션 문제를 방지하는 게 가장 중요할 때 선택하면 돼요.
```sql CREATE TABLE users ( user_id BIGINT, username VARCHAR(100), ... ) PARTITION BY HASH (user_id);
CREATE TABLE users_p0 PARTITION OF users FOR VALUES WITH (MODULUS 4, REMAINDER 0); CREATE TABLE users_p1 PARTITION OF users FOR VALUES WITH (MODULUS 4, REMAINDER 1); ```
리스트(List) 파티셔닝은 미리 정의된 값 목록을 기반으로 데이터를 그룹화해요. 지역이나 부서 같은 잘 변하지 않는 값에 적합하죠.
```sql CREATE TABLE events ( id BIGINT, region TEXT, ... ) PARTITION BY LIST (region);
CREATE TABLE events_us PARTITION OF events FOR VALUES IN ('us-east', 'us-west'); CREATE TABLE events_eu PARTITION OF events FOR VALUES IN ('eu-west', 'eu-central'); ```
복합 파티셔닝 — 쪼갠 걸 한 번 더 쪼갠다
파티셔닝 구조에 세분화 단계를 하나 더 얹는 거예요. 날짜로 범위 파티셔닝 후 각 파티션 내부를 지역으로 리스트 파티셔닝한다거나. 초대형/이력 데이터에 주로 활용되고, 리스트/리스트, 리스트/범위, 범위/해시 등 다양한 조합이 가능해요.
가장 널리 쓰이는 범위/리스트 조합부터 볼게요.
```sql -- 루트: 날짜 기준 Range CREATE TABLE event_logs ( log_id BIGSERIAL NOT NULL, event_date DATE NOT NULL, region VARCHAR(10) NOT NULL, severity VARCHAR(10) NOT NULL, message TEXT ) PARTITION BY RANGE (event_date);
-- 2024년 파티션 → 내부를 region(List)으로 재분할 CREATE TABLE event_logs_2024 PARTITION OF event_logs FOR VALUES FROM ('2024-01-01') TO ('2025-01-01') PARTITION BY LIST (region);
CREATE TABLE event_logs_2024_kr PARTITION OF event_logs_2024 FOR VALUES IN ('KR'); CREATE TABLE event_logs_2024_us PARTITION OF event_logs_2024 FOR VALUES IN ('US'); CREATE TABLE event_logs_2024_eu PARTITION OF event_logs_2024 FOR VALUES IN ('EU'); CREATE TABLE event_logs_2024_etc PARTITION OF event_logs_2024 DEFAULT; ```
프루닝이 날짜 범위로 먼저 탐색하고, region 기준으로 서브 파티션을 찾아서 해당 서브 파티션 하나만 스캔하게 돼요. 두 단계 필터가 걸리는 셈이죠.
2개의 시간 축을 사용하는 경우에는 범위/범위 조합도 가능해요. 주문일로 먼저 나누고 각 파티션 내부를 배송일로 다시 분기별로 쪼개는 식이에요.
```sql CREATE TABLE orders ( order_id BIGINT NOT NULL, order_date DATE NOT NULL, ship_date DATE, customer_id BIGINT NOT NULL, amount NUMERIC(12,2) ) PARTITION BY RANGE (order_date);
CREATE TABLE orders_2024 PARTITION OF orders FOR VALUES FROM ('2024-01-01') TO ('2025-01-01') PARTITION BY RANGE (ship_date);
CREATE TABLE orders_2024_ship_q1 PARTITION OF orders_2024 FOR VALUES FROM ('2024-01-01') TO ('2024-04-01'); CREATE TABLE orders_2024_ship_q2 PARTITION OF orders_2024 FOR VALUES FROM ('2024-04-01') TO ('2024-07-01'); ```
범위/해시 조합은 대형 거래 테이블이나 대규모 이력 테이블에 맞아요. 연도별 Range 파티션 안에 user_id 기준 Hash 서브파티션을 4개 버킷으로 두는 식이죠.
```sql CREATE TABLE transactions ( tx_id BIGINT NOT NULL, tx_date DATE NOT NULL, user_id BIGINT NOT NULL, amount NUMERIC(12,2), status VARCHAR(20) ) PARTITION BY RANGE (tx_date);
CREATE TABLE transactions_2024 PARTITION OF transactions FOR VALUES FROM ('2024-01-01') TO ('2025-01-01') PARTITION BY HASH (user_id);
CREATE TABLE transactions_2024_h0 PARTITION OF transactions_2024 FOR VALUES WITH (MODULUS 4, REMAINDER 0); -- h1, h2, h3 동일 패턴
CREATE INDEX ON transactions_2024_h0 (user_id, tx_date); ```
인덱스가 서브파티션 단위로 생성된다는 점도 기억해야 돼요.
수직 파티셔닝 — 컬럼을 기준으로 분리한다
수직 파티셔닝은 단일 테이블을 컬럼 기준으로 여러 개의 작은 테이블로 분할하는 개념이에요. 각 테이블이 원본의 일부 컬럼만 가지고, 동일한 PK를 공유하죠.
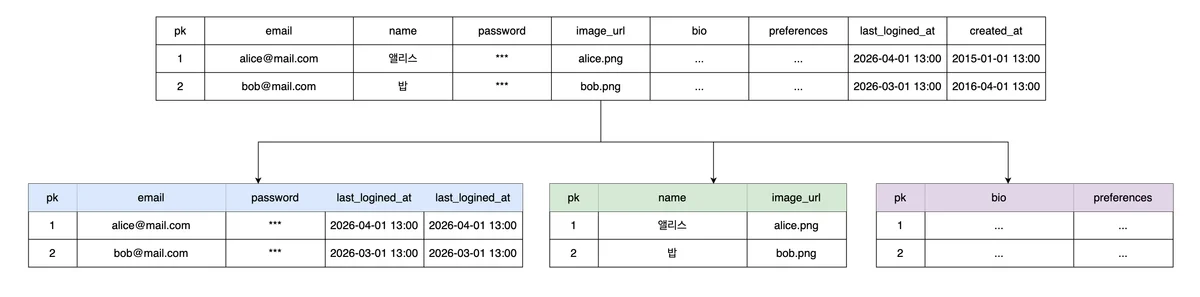
자주 사용되는 hot 컬럼과 드물게 사용되는 cold 컬럼을 분리해서 Disk I/O 오버헤드와 메모리 공간 효율성을 높이는 거예요. 잘 생각해 보면 테이블 스키마를 완전히 재설계하는 것과 같아요.
예를 들어 users 테이블에 로그인 시 쓰는 컬럼(email, password, last_login), 프로필 조회 시 쓰는 컬럼(name, image_url), 마이페이지 진입 시 쓰는 컬럼(bio, preferences)이 섞여 있으면 비효율이 생겨요. cold 컬럼이 많아질수록 비용 비효율은 커지고요.
```sql -- 로그인 시 CREATE TABLE users_auth ( user_id BIGINT PRIMARY KEY, email VARCHAR(255) NOT NULL UNIQUE, password VARCHAR(255) NOT NULL, last_login TIMESTAMP, created_at TIMESTAMP );
-- 프로필 조회 시 CREATE TABLE users_profile ( user_id BIGINT PRIMARY KEY REFERENCES users_auth(user_id), name VARCHAR(100), image_url VARCHAR(512) );
-- 마이페이지 진입 시 CREATE TABLE users_detail ( user_id BIGINT PRIMARY KEY REFERENCES users_auth(user_id), bio TEXT, preferences JSONB ); ```
조회 쿼리도 훨씬 간결해져요. 로그인은 `users_auth`만, 프로필은 `users_auth`와 `users_profile`을 JOIN, 마이페이지는 세 테이블 JOIN. 유스케이스별 도메인 로직 분리에 익숙한 개발자라면 이미 비슷한 경험이 있을 거예요.
Range가 맞는 곳에 Hash를 쓰면 프루닝이 사라진다
파티셔닝 전략에 정답은 없어요. 근데 오답은 확실히 있어요. Range가 맞는 테이블에 Hash를 쓰면 프루닝이 사라지고, 수직 분리가 필요한 곳에 수평 파티셔닝만 고집하면 캐시 효율은 여전히 나빠요.
결국 경험이에요. 대규모 데이터를 자주, 많이 다뤄 볼수록 쿼리 패턴을 보는 눈이 생기고, 적합한 전략을 선택하는 속도도 빨라지거든요. 더 나아가면 테이블 분리를 넘어 서비스 분리까지 고민할 수 있게 되고요.
(솔직히 각 전략을 처음 보면 "이걸 언제 다 쓰지?" 싶은데, 데이터가 커지면 자연스럽게 필요해져요.)
아는 만큼 보이고, 해본 만큼 빨라진다. 이게 파티셔닝 전략 선택의 전부예요.