flex가 AI 접근성 4.18점을 받은 이유 — 사람을 위한 규율이 에이전트도 지킨다

Gradle 플러그인을 만들 때, 2년 뒤에 AI 에이전트의 가드레일이 될 거라고 예상했을까요? 아니었대요. Outbox 패턴을 라이브러리로 만들 때, 이게 인가 시스템의 인프라가 될 줄도 몰랐고요. Hexagonal의 Adapter 교체 가능성이, AI가 만든 코드의 acceptance를 증명하는 standalone 환경으로 이어질 줄도.
flex 백엔드 시리즈 6편. 지난 다섯 편에서 컴파일이 아키텍처를 지키고, 이벤트 인프라가 라이브러리로 작동하고, 인가 시스템이 그 레일 위에 올라가는 인과 사슬을 따라왔는데, 이번엔 그 구조가 예상 밖의 곳에서 힘을 발휘하는 이야기예요. 개발 도구로서의 AI — 코딩 에이전트와의 협업.
자연어 지시 대신 컴파일러가 때린다
AI 코딩 에이전트에게 코드를 작성시킬 때 가장 큰 과제가 뭐냐면, 아키텍처를 지키게 하는 거예요. "이 모듈에서 저 모듈을 직접 참조하면 안 돼", "트랜잭션 경계는 여기까지야" — 이렇게 자연어로 가이드라인을 줄 수는 있지만, 에이전트가 맥락을 잘못 해석할 여지가 항상 있잖아요. 말은 모호하니까요.
flex의 Gradle 멀티모듈 + Hexagonal 구조에서는 다르게 풀려요. 에이전트가 허용되지 않은 의존성을 추가하면 빌드가 실패해요. 말로 하는 피드백이 아니라, 컴파일러가 주는 명확한 피드백. 에이전트 입장에서는 "이건 안 된다"를 추론할 필요 없이, 빌드 결과를 보고 방향을 수정하면 돼요.
이게 백엔드에서만 먹히는 건 아니에요. flex-terraform의 Pulumi 프로젝트도 마찬가지거든요. Kotlin으로 IaC를 작성하니까, AI 에이전트가 잘못된 서브넷 설정이나 누락된 인터페이스를 생성하면 `./gradlew build`가 즉시 잡아내요. HCL로 작성된 Terraform에서는 `plan`을 돌려야만 — 그것도 실제 클라우드 credential이 있어야만 — 알 수 있었던 오류인데요. 실제로 flex-terraform Pulumi 프로젝트의 모든 코드 변경은 Claude Code와의 대화로 생성됐다고 해요.
1화에서 "사람을 위해" 만든 빌드 규율. 그게 AI 시대에도 그대로 작동하는 거예요.
Standalone 조립 — "막는 것"을 넘어 "끼워 맞추는 것"으로
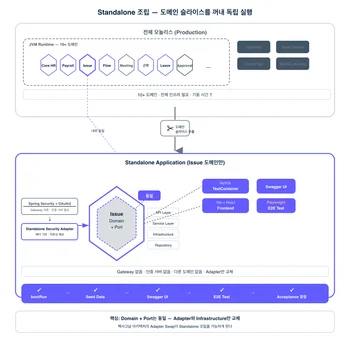
Hexagonal 구조의 진짜 위력은 "막는 것"이 아니라 "조립할 수 있게 하는 것"에 있다는 게 flex의 주장이에요.
도메인 모듈이 flex-skeleton 템플릿 기반으로 만들어지니까 Port/Adapter 경계가 명확하잖아요. 이 경계가 명확하기 때문에, 특정 도메인만 꺼내서 Adapter를 교체하고 독립 실행 가능한 애플리케이션으로 조립할 수 있어요.
구체적인 사례가 있어요. flex-flow-backend의 Issue 도메인에 `standalone-app`이라는 모듈이 있는데, Issue의 API, Service, Infrastructure, Repository 모듈을 조립하되 프로덕션의 Spring Security + OAuth2 인증 대신 단순 헤더 기반의 Standalone Security Adapter를 끼워 넣어요. Gateway도 없고, 인증 서버도 없고, 다른 도메인도 없이 — Issue 도메인만 독립으로 기동되는 거예요.
여기서 끝이 아니에요. 이 standalone 환경 위에 Swagger UI, 시드 데이터, 심지어 Vite + React 프론트엔드와 Playwright E2E 테스트까지 올라가요. `./gradlew :issue:standalone-app:e2eTestWithServer` 한 줄이면 MySQL TestContainer 위에 Issue 도메인이 뜨고, 프론트엔드가 빌드되고, E2E 시나리오가 자동으로 돌아가요.
이게 가능한 이유? Port/Adapter 구조에서 Adapter가 교체 가능하기 때문. 도메인 로직에 손 안 대고 외부 연결점만 바꾸면 돼요. 5화의 타임머신(시간 축 교체), Rewrite Host(공간 축 교체)와 같은 사고방식인데, Standalone App은 구조 축을 교체하는 거 — 전체 모놀리스 대신 도메인 슬라이스만 조립해서 검증하는 거죠.
"이거 진짜 돌아가?" — Code Review의 병목이 바뀐다
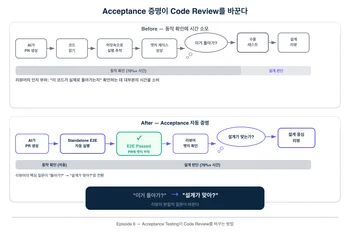
이 standalone 조립이 AI 시대에 특히 중요한 이유가 있어요. Code Review의 병목을 바꾸거든요.
AI 에이전트가 PR을 만들었을 때 리뷰어의 첫 반응. "이거 진짜 돌아가?" 코드를 읽고, 머릿속에서 실행 흐름을 따라가고, 엣지 케이스를 상상해야 하니까 인지 부하가 엄청나요.
근데 그 PR에 standalone 환경에서의 E2E 테스트 통과 결과가 붙어 있으면? "돌아가는지"는 이미 증명된 거잖아요. 리뷰어는 "동작 확인" 대신 "설계 판단"에 집중할 수 있어요. "이 추상화가 이 맥락에서 맞는가?", "이 모듈 경계가 적절한가?", "이 변경이 다른 도메인에 의도치 않은 영향을 주지 않는가?" — 진짜 중요한 질문들에요.
flex에서는 이걸 "Acceptance 증명 우선"이라 불러요. AI가 만든 코드든 사람이 만든 코드든, PR에 acceptance가 자동으로 증명되면 리뷰의 무게 중심이 "이거 돌아가?"에서 "이 설계가 맞아?"로 이동하는 거예요. AI가 코드를 더 많이 생성하는 시대에, 엔지니어의 시간을 가장 높은 가치의 판단에 쓰게 해주는 구조적 변화. 결국 1화의 "문서가 아니라 빌드가 지킨다"와 같은 사고방식이고요.
L1~L5, AI 접근성을 점수로 매기다
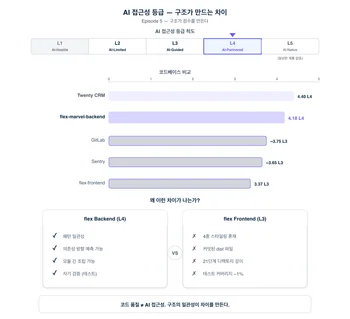
잠깐, 여기서 좀 흥미로운 이야기가 나와요. flex는 내부적으로 코드베이스의 "AI 접근성"을 평가하는 프레임워크를 만들어 쓰고 있거든요. 코드 품질과 AI 접근성을 2축으로 놓고, L1(AI-Hostile)부터 L5(AI-Native)까지 5단계 평가.
결과가 재밌어요. flex-marvel-backend는 L4(AI-Partnered, 4.18/5.0) 등급. Twenty CRM을 제외한 대부분의 오픈소스 제품 코드베이스 — GitLab, Sentry, Mattermost, Grafana 같은 것들 — 보다 높은 수치였어요.
같은 회사 안에서도 차이가 명확했는데, Frontend 코드베이스는 코드 품질 자체는 4.1로 높았지만 AI 접근성이 2.63에 그쳐서 L3(AI-Guided) 등급이었어요. 이 격차의 원인은 코드를 잘 짰느냐가 아니라, 구조가 일관되느냐였다는 거예요. 패턴 일관성, 의존성 방향의 예측 가능성, 모듈 간 조립 가능성. (현재까지 L5를 달성한 제품 코드베이스는 업계에 존재하지 않는다고 해요.)
코드 품질 4.1인데 AI 접근성 2.63이라는 숫자가 시사하는 건, "좋은 코드"와 "AI가 잘 읽을 수 있는 코드"가 다른 차원의 문제라는 거예요. 1화에서 깎아낸 경계가 AI 시대의 경쟁력으로 전환되고 있는 셈이죠.
오늘의 문제를 제대로 풀면, 내일의 자격이 생긴다
여섯 편에 걸쳐 이야기한 걸 다시 따라가보면. 빌드가 아키텍처를 지키고, 아키텍처가 이벤트 인프라의 라이브러리화를 가능하게 하고, 이벤트 인프라가 인가 시스템의 기반을 제공하고, 같은 설계 원칙이 멀티클라우드, Observability, IaC, 배포 파이프라인까지 관통하고, 이 모든 게 AI 에이전트와의 협업에서 가드레일이자 발판이 돼요.
각각의 결정은 그 시점에서 눈앞의 문제를 풀기 위한 것이었어요. IaC를 Kotlin + 인터페이스 기반으로 짤 때, AI 에이전트가 인프라 변경을 안전하게 생성하는 도구가 될 줄은 몰랐다고요.
근데 좋은 아키텍처의 특성이 바로 이거 아닐까요. 오늘의 문제를 제대로 풀면, 내일의 문제를 풀 수 있는 자격이 함께 생긴다는 것.
flex 백엔드는 50개 이상의 레포, 3500개 이상의 모듈이 서로 의존하는 생태계라고 해요. 다음 마지막 화에서는 이 구조의 일관성이 레포 경계를 넘어 전체 생태계 수준에서 작동할 때 어떤 일이 벌어지는지를 다룬다고 하는데, 의존성의 방향을 따라 변화가 레포 간에 자동으로 전파되고, 시리즈 전체의 인과 사슬이 하나의 자동화된 파이프라인으로 수렴하는 이야기. 솔직히 궁금하긴 하네요.