젬마 4, 라즈베리파이에서도 돌아가는데 20배 큰 모델을 이긴다
구글이 젬마 4를 내놨어요. 오픈웨이트 모델의 최신 버전인데, "고급 추론과 에이전트 기반 워크플로우를 위해 특수 설계됐다"고 구글이 직접 강조했거든요. 아파치 2.0 라이선스. 누구나 가져다 쓸 수 있어요.

젬마 시리즈가 처음 나온 이후 4억 회 이상 다운로드됐고, 10만 개 넘는 파생 모델이 만들어졌어요. 4억 회. 오픈소스 AI 생태계에서 이 정도면 사실상 인프라 수준이에요. 근데 이번 젬마 4는 좀 다른 걸 노리고 있어요.
4개 크기, 전혀 다른 타겟
모델이 네 가지 크기로 나왔어요. Effective 2B(E2B), Effective 4B(E4B), 26B Mixture of Experts(MoE), 31B Dense. 이름만 보면 그냥 크기 차이 같지만 설계 철학이 달라요.
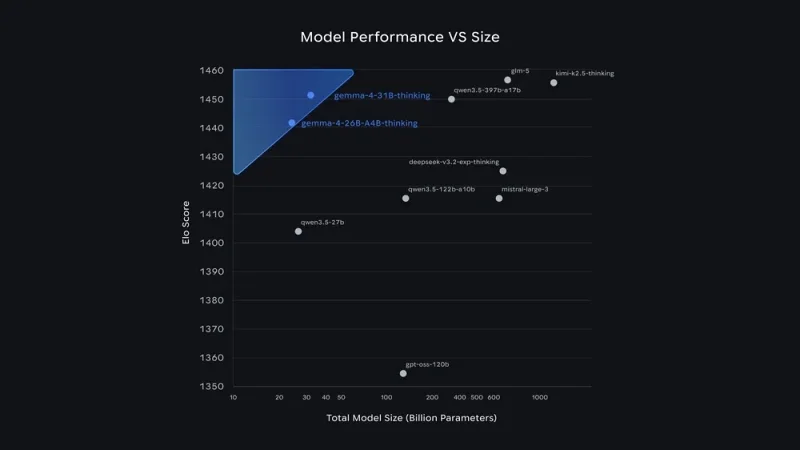
31B Dense는 출력 품질에 올인한 모델이에요. 미세 조정을 위한 기반 모델로 쓸 수 있도록 설계됐고, 현재 Arena AI 텍스트 리더보드에서 오픈 모델 기준 3위를 찍었어요. 26B MoE는 레이턴시에 초점을 맞춘 건데, 전체 매개변수 중 약 38억 개만 활성화해서 빠른 속도를 제공하더라고요. 리더보드 6위. 구글이 "20배 큰 모델도 압도하는 성능"이라고 했는데, 26B짜리가 500B급을 이겼다는 뜻인지는 좀 더 뜯어볼 필요가 있긴 해요.
벤치마크 결과를 보면 수학 및 복합 지시 이행 같은 고난이도 작업에서 상당한 성능 향상을 보여줬어요.
함수 호출, 구조화된 JSON 출력, 네이티브 시스템 지침을 기본 지원한다는 것도 짚어야 할 부분이에요. 에이전트를 만들 때 외부 API랑 상호작용하고 워크플로우를 안정적으로 실행하는 자율형 에이전트를 구축할 수 있다는 거거든요. 코드 생성, 이미지 및 오디오 입출력 처리, 140개 이상 언어 지원까지. 스펙시트만 보면 상당히 공격적이에요.
작은 모델이 진짜 승부처다
근데 개인적으로 더 눈이 간 건 E2B랑 E4B예요.
이 두 모델은 온디바이스 AI에 특화됐어요. 매개변수 수보다 멀티모달 기능, 낮은 레이턴시, 생태계 연동을 우선적으로 고려해서 설계됐다는 게 구글의 설명이에요. 추론 시 각각 약 20억, 40억 규모의 파라미터만 활용해서 메모리 사용량과 배터리 소모를 최소화하고요.
재미있는 건 하드웨어 파트너십이에요. 구글 픽셀 팀은 물론이고 퀄컴, 미디어텍 같은 칩셋 업체들과 긴밀하게 협력했거든요. 결과적으로 스마트폰, 라즈베리 파이, 엔비디아 젯슨나노에서 제로에 가까운 레이턴시로 오프라인 실행이 돼요. 라즈베리 파이에서 돌아가는 AI 모델이 Arena 리더보드 상위권 모델과 같은 패밀리라는 거잖아요. (솔직히 이 조합이 좀 웃기면서도 대단해요.)
안드로이드 개발자는 AI코어 디벨로퍼 프리뷰에서 에이전트 기반 흐름의 프로토타입을 제작해서 제미나이 나노 4와의 향후 호환성을 확보할 수 있다고 해요.
어디서 쓸 수 있나
26B/31B 모델은 단일 80GB 엔비디아 H100 GPU에서 비양자화 bfloat16 가중치로 돌릴 수 있어요. 양자화 버전은 일반 소비자용 GPU에서도 돌아가고요. IDE, 코드 어시스턴트, 에이전틱 워크플로우를 지원하니까 개인 워크스테이션에서 프론티어급 추론을 돌린다는 이야기가 허풍만은 아닌 거죠.
구글 AI 스튜디오에서 31B/26B를, 구글 AI 엣지 갤러리에서 E4B/E2B를 바로 이용해볼 수 있어요. 허깅페이스, vLLM, 올라마, 엔비디아 NIM에서도 돌리 수 있고, 모델 가중치는 허깅페이스, 캐글, 올라마에서 다운로드 가능해요. 안드로이드 스튜디오 에이전트 모드와 ML Kit GenAI Prompt API로 프로덕션 환경까지 확장할 수 있다고 하고요.
하드웨어 최적화 범위도 넓어요. 엔비디아 젯슨나노와 블랙웰 GPU, 오픈소스 ROCm 스택을 통한 AMD GPU 연동, 구글 클라우드 TPU로 대규모 확장. 젬마 4가 제미나이 3와 동일한 연구 및 기술 기반으로 개발됐다는 구글의 말이 사실이라면, 이건 폐쇄형 모델의 기술이 오픈웨이트로 빠르게 흘러내려오고 있다는 신호예요. 경쟁사 입장에서는 꽤 불편한 소식이겠죠.