LLM이 표를 못 읽는 이유, 그리고 RAG와 SQL을 섞어야 하는 이유

"제일 비싼 상품이 뭐에요?" 이 질문에 벡터 검색은 답할 수 없어요. 숫자를 이용한 상대적 비교가 아니라, 자연어 상의 절대적 유사도를 기반으로 검색하기 때문이죠. 채널톡의 AI 에이전트 ALF는 고객사의 도큐먼트를 기반으로 답변을 제공하고 있었는데, "엑셀 파일만 올리면 상품 재고나 가격을 안내해줬으면 좋겠다"는 수요가 계속 들어왔어요. 문제는 LLM이 표 데이터를 근본적으로 이해하기 어렵다는 점이었어요.
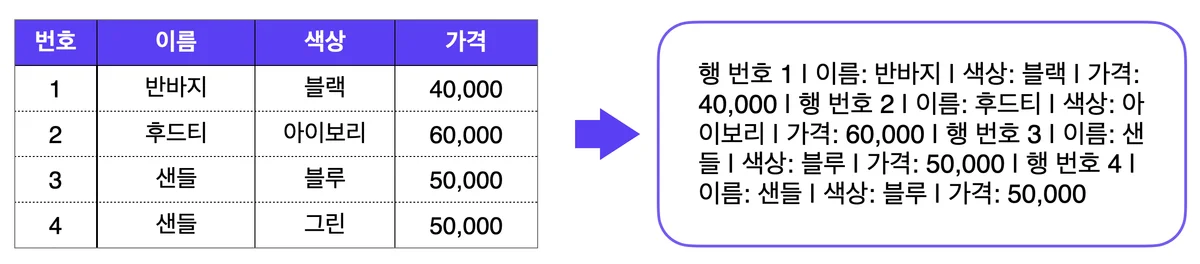
1차원 텍스트로 학습된 LLM에게 2차원 표는 패턴이 파괴된 데이터다
LLM은 1차원의 텍스트를 읽기 위해 학습된 모델이에요. 표를 보려면 1차원으로 펼쳐주는 선형화(Linearization) 작업이 필요한데, 이 과정에서 LLM이 의존하는 두 가지 편향이 무너지죠. 첫째, 가까이 있는 단어는 서로 연관이 높다는 Proximity 편향이 깨져요. 행이 바뀔 때 서로 관련 없는 문자열이 이어붙게 되거든요. 둘째, 이후에 오는 단어가 이전 단어에 영향을 받는다는 Causality 편향도 무너져요. 표의 행과 열은 대부분 순서와 무관하니까요.
RAG에서도 표를 사용하기 어려워요. 각각의 행이 하나의 의미적 단위를 구성한다고 말하기 힘들고, "제일 비싼 상품"처럼 비교가 필요한 질문은 벡터 유사도로는 찾을 수 없거든요. Text-to-SQL도 만능은 아니에요. 회색을 표현하기 위해 아이언 그레이, 차콜, 스페이스 그레이 등 너무 많은 이름이 사용되는 현실에서, 정확한 매칭 기반의 SQL만으로는 한계가 분명했어요.
벡터 검색으로 이름을 찾고, SQL로 필터링하는 하이브리드 전략
Table Agent의 핵심 아이디어는 두 기술의 강점을 조합하는 거예요. 필터링, 정렬 같은 세밀한 작업은 SQL 쿼리가 담당하고, 상품명이나 색상처럼 정확한 이름을 찾아야 할 때는 벡터 검색을 사용하는 거죠.
인덱스 단위가 흥미로운데, 하나의 행이 아니라 하나의 셀로 정했어요. 중복을 제거하고 숫자나 범주형 자료도 제외하면, 실제로 벡터 데이터베이스에 올라가는 벡터 수는 전체 셀 수의 1~2%에 불과했어요. LLM을 동원해서 벡터 검색이 필요한 열(상품명, 매장명, 색상 등)과 필요 없는 열(상품 코드, 사이즈 등)을 미리 분류하는 전처리도 추가했죠. 결국 "표를 그대로 LLM에 넣으면 이해하지 못한다"는 문제에 대해, 데이터를 적절히 쪼개고 적절한 도구를 조합하는 것이 답이라는 실전 교훈을 보여주는 사례예요.