하루 400만 건 광고 집계, Flink로 7일치를 실시간으로 잡다
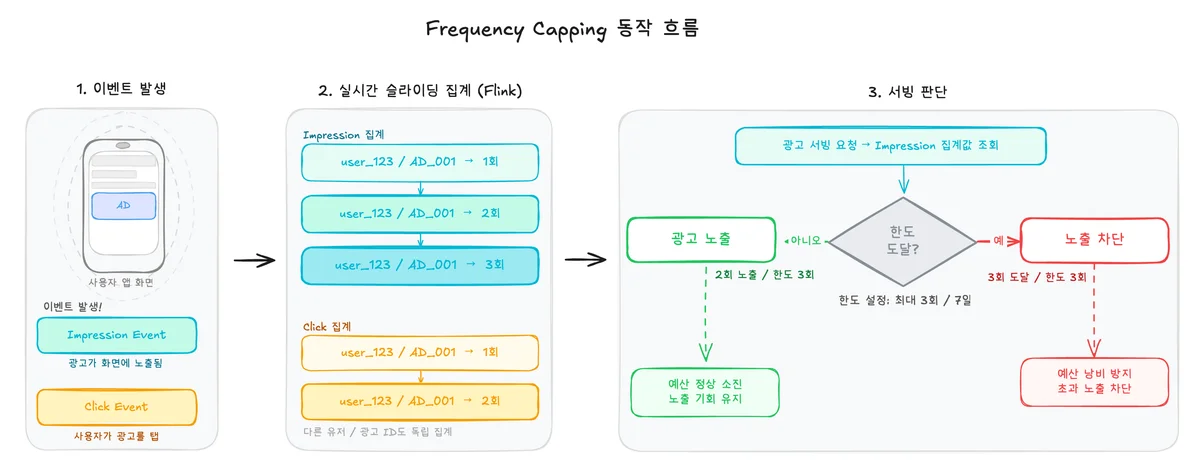
광고주가 "하루 3회까지만 노출"이라고 걸어뒀는데 실제로는 7회 노출됐어요. 이게 바로 돈이 새는 순간이에요. 반대로 2회만 나갔는데 한도라고 판단되면, 그 광고주는 한 번의 기회를 날린 셈이에요. 토스 Data Service Platform Team이 장기 구간 집계까지 Flink로 옮긴 이유도 결국 여기서 시작해요. 집계 오차는 곧 비즈니스 오차.
이 글은 1분~30분을 맡던 Flink 앱에 1시간~7일 구간까지 덧붙이면서 생긴 이야기예요. 결론부터 말하면, Head·Mid·Tail 세 계층을 합산하던 서빙이 Redis 단일 조회로 바뀌었고, 하루 75회 돌던 Airflow DAG는 25회로 줄었어요. 본문의 코드·설정은 Apache Flink 1.20.1, flink-connector-kafka 3.3.0 기준입니다.
왜 배치로는 충분하지 않았나
기존 구조는 세 계층이었어요. Head(당일·전일 실시간 Redis), Mid(D-2~D-7을 매일 03:15에 Spark가 선집계), Tail(Head와 Mid 경계 ±1시간을 매시간 07분에 보정). 16:30에 "최근 7일"을 물으면 이 네 구간을 순서대로 긁어 합산해요. Redis 조회가 최대 4회.
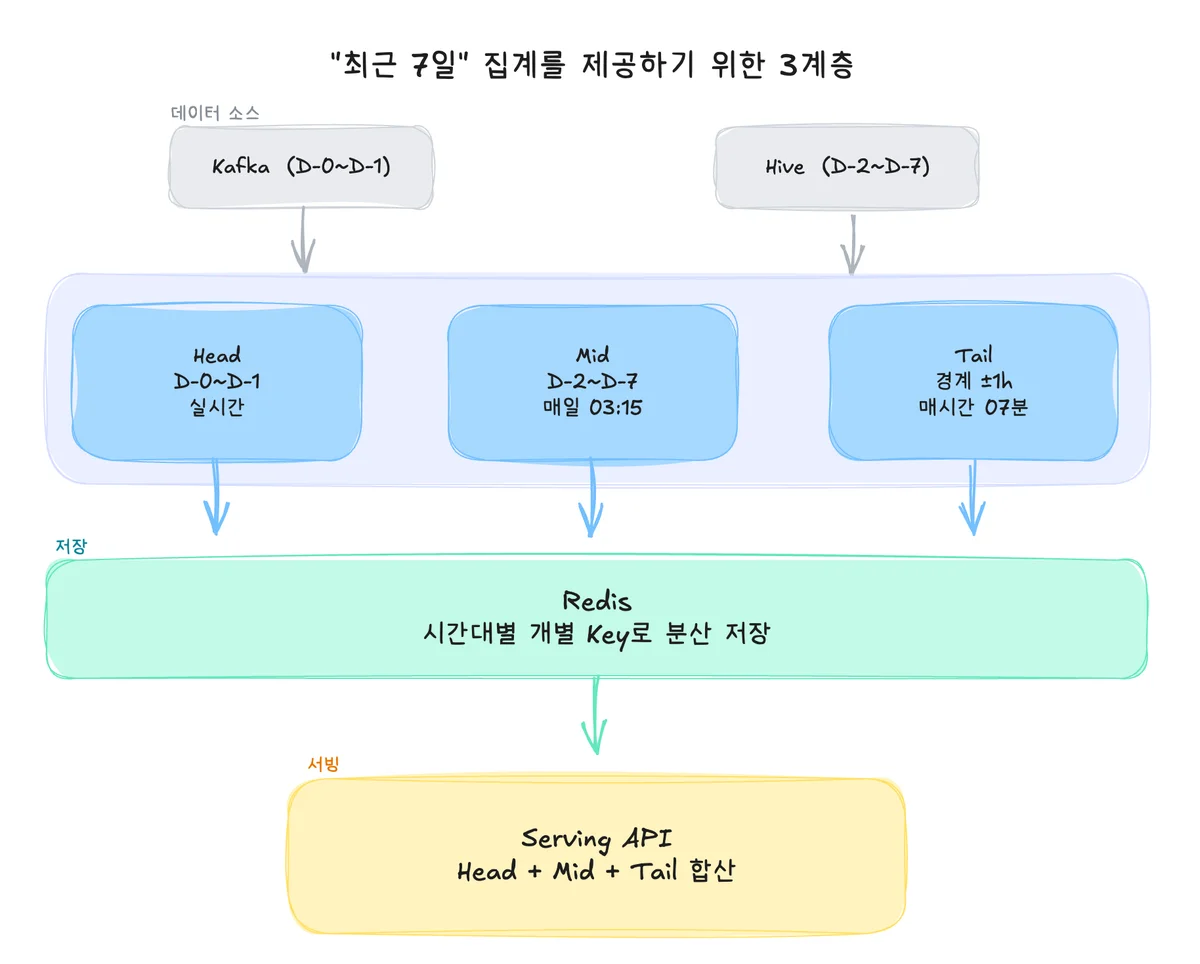
숫자로 보면 더 와닿아요. Mid·Tail 관련 DAG만 하루 75번 돌았어요. 서빙 레이어는 시간 구간별로 계산 경로가 달라서, 새 팀원이 전체 흐름 파악하는 데 오래 걸리는 구조였고요. 결국 돈 문제.
그리고 배치는 시간 단위로 집계를 절삭해요. 이벤트별 만료 추적은 태생적으로 안 돼요. 30일치 고정 집계처럼 실시간 이점이 작은 구간은 여전히 배치로 돌리고 있고(Kafka 리텐션 초과 구간은 재처리도 못 하니까요), 장기 슬라이딩만 Flink로 넘기기로 한 결정이었어요.
앱을 쪼갠 이유 — 병목 패턴이 달라서
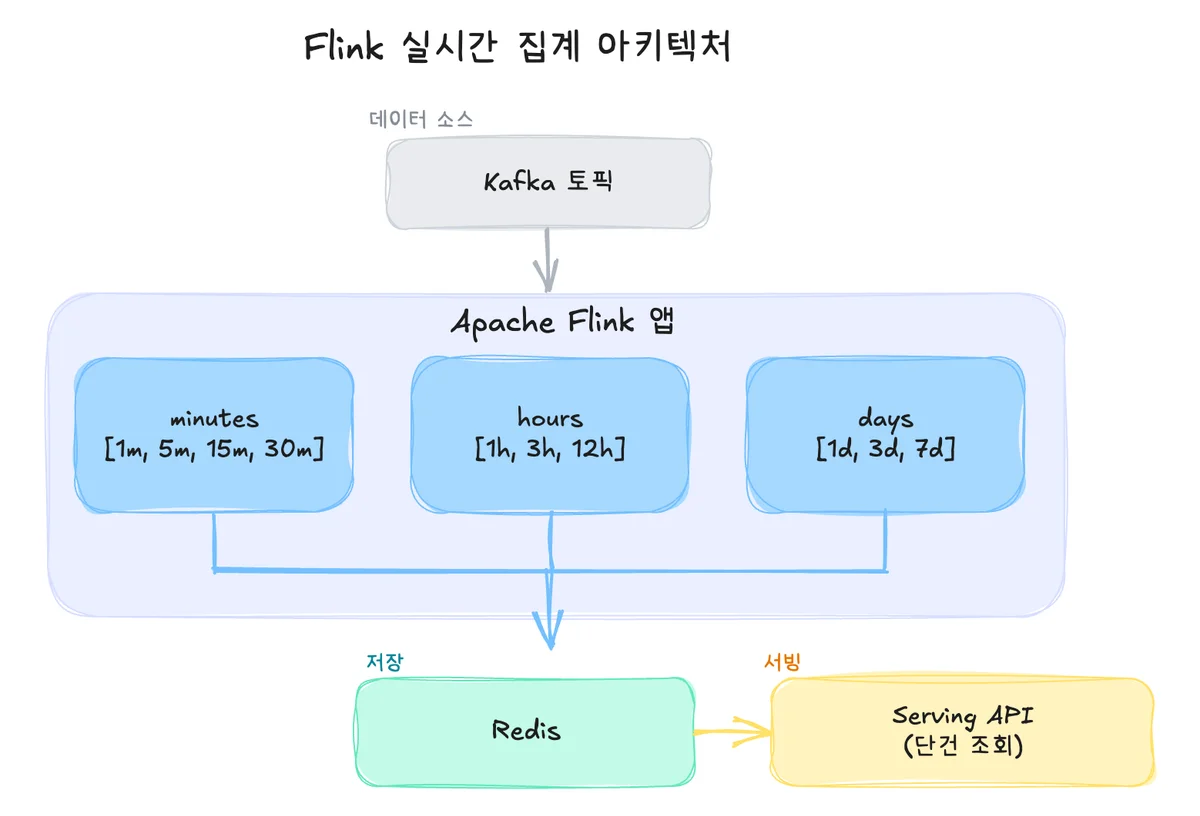
가장 먼저 결정한 건 앱 분리였어요. 단일 앱으로 가는 대신 minutes / hours / days 3개로 나눴어요. 구간마다 병목이 딴판이라는 이유 하나 때문이에요.
- minutes: 1~30분짜리라 이벤트당 만료 처리가 가장 빈번. Write Buffer Manager 압박 → Write Stall로 직행하는 Write 집약형.
- hours: TTL 최대 12시간이라 State에 누적되는 광고 ID가 많음. Filter Block Cache Miss로 인한 CPU 포화가 1차 병목. Redis 쓰기의 O(N) 스캔이 CPU 경쟁 가중.
- days: 규모 자체가 다른 차원. 7일 윈도우 하나의 live-sst-files-size만 68GB, Savepoint는 220~230GB. Checkpoint I/O 자체가 파이프라인 병목.
같은 코드베이스를 공유하되 RocksDB 설정은 완전히 다르게 갔어요. 한 쪽 최적화가 다른 쪽에 부작용 내는 걸 피하기 위한 조치였고요. 단일 SSOT(State가 집계의 단일 진실 공급원) 원칙은 유지. 장애·재시작 시에도 State에서 Redis를 재구성할 수 있도록.
전환 순간을 통과하는 게 가장 어렵다
기술적으로 제일 까다로운 건 실시간 전환 이후가 아니라 "전환 순간"이었어요.
문제는 이래요. 7일치 과거 데이터를 채우는 백필(Backfill)은 카운트 +1만 해요. 만료 타이머는 안 걸어요. 반면 실시간 이벤트를 처리하는 캐치업(Catch-up)은 +1과 함께 슬라이딩 윈도우를 벗어난 이벤트에 -1을 걸어야 하고요. 둘을 하나의 파이프라인에 합치면? 과거 데이터 쌓는 도중에 만료 타이머가 먼저 발화해 아직 쌓이지도 않은 값이 감소해버려요. 집계가 틀어지는 거예요.
batchMode도 검토했어요. Batch Job이 FINISHED되면 State가 폐기된다는 게 문제였죠. 재구축한 State를 Redis 초기값으로 써줄 경로가 없어요. Hive+Spark로 과거를 뽑는 방안도 살펴봤는데, 정합성이 핵심인 앱에 외부 시스템 두 개를 더 끼우는 게 부담이었어요. Kafka+Flink 단일 시스템 안에서 푸는 걸 원칙으로 삼았습니다.
결과는 2단계 파이프라인이에요. 백필은 Consumer Group을 분리해 1/3/7일치 이벤트를 읽고, 카운트만 올린 뒤 Redis에 한 번 동기화하고 FINISHED. 캐치업은 State를 처음부터 다시 만들어요. 백필의 State를 Savepoint로 살릴 순 없어요. 타이머가 없으니 감소가 영원히 발화 안 하거든요. SCAN_END 시점부터 Redis에 반영 시작. 여기서 같은 group을 쓰면 백필 이후 Committed Offset이 앞서 나가 캐치업 구간이 통째로 누락되니까, 반드시 별도 group을 써야 해요.

경계를 정확히 통과하려면 세 가지가 맞물려야 했어요.
첫째, Redis 쓰기 조건을 watermark가 아니라 각 이벤트의 eventTime으로 잡았어요. watermark 기준으로 두면 idle한 파티션 하나가 전체 진행을 잡아 쓰기를 영구 차단해요. (운영 중 만나면 꽤 무서운 상황이에요.) eventTime 기준 독립 평가로 이 구조적 덫을 피했어요.
둘째, withIdleness 60초. 너무 짧으면(예: 1초) Bounded Source가 MAX_WATERMARK를 emit하기 직전 특정 파티션이 Idle로 오감지돼요. StatusWatermarkValve가 그 파티션의 MAX_WATERMARK를 downstream으로 안 넘겨요. 60초면 Bounded Source가 FINISHED로 전환되는 시간보다 충분히 길어 오감지가 먼저 일어날 수 없어요.
셋째, timerState TTL을 슬라이딩 윈도우 만료보다 넉넉하게. 처리 지연 시 타이머는 발화하는데 timerState는 만료돼서 null이 나오면, 감소가 스킵돼요. 카운트가 줄지 않아 집계가 실제보다 높게 남아버리는 거예요. 수동으로 finally에서 정리하되 TTL은 넉넉하게.
minutes — Write Stall과의 싸움
처음 마주친 건 Write Stall이었어요. RocksDB가 쓰기를 스스로 멈추는 현상. 원인은 Write Buffer Manager(WBM) 압박이었고요.
RocksDB는 쓰기를 MemTable에 쌓다가 일정 크기가 넘으면 SST 파일로 내려보내요. L0부터 L6까지 레벨 구조로 관리되고, Flink는 State를 Column Family(CF) 단위로 관리해요. WBM max가 CF당 write_buffer_size(기본 64MB)보다 작으면 강제 Flush. 쌓인 L0가 임계를 넘으면 쓰기 속도가 제한되거나 아예 Stop. Stall이 지연을 부르고, 지연이 또 Flush를 쌓고. 자기강화 사이클.
초기엔 CF당 WBM budget이 16MB였어요. write_buffer_size(64MB)보다 훨씬 작아서 강제 Flush가 반복됐죠. 해결은 managed 500MB → 1200MB, WBR 0.25 → 0.5로 끌어올리는 것. CF당 budget이 16MB → 75MB로 오르면서 write_buffer_size를 넘어섰고, Stall도 사라졌어요. 백그라운드 Compaction이 정상화됐고, L0 파일이 줄어 read 탐색 범위도 감소. Cache Hit Rate는 62~64%에서 99~100%까지 올라갔어요.
writebuffer.count=3, writebuffer.number-to-merge=2도 함께 조정했는데, 이건 근본 해결이 아니라 Stall 구간을 줄이는 보조 역할이에요. WBM 절대량 증설이 진짜 답이었어요. write_buffer_size만 올리는 건 per-CF 크기만 키울 뿐 WBM 압박은 남아서 해결이 안 돼요.
hours — CPU 96%가 Filter Block Read에 먹히고 있었다
hours 앱은 진단부터 달랐어요. CPU가 포화되는데, Compaction까지 밀리는 상태. async-profiler로 1,766 samples를 수집해서 보니 답이 나왔어요.
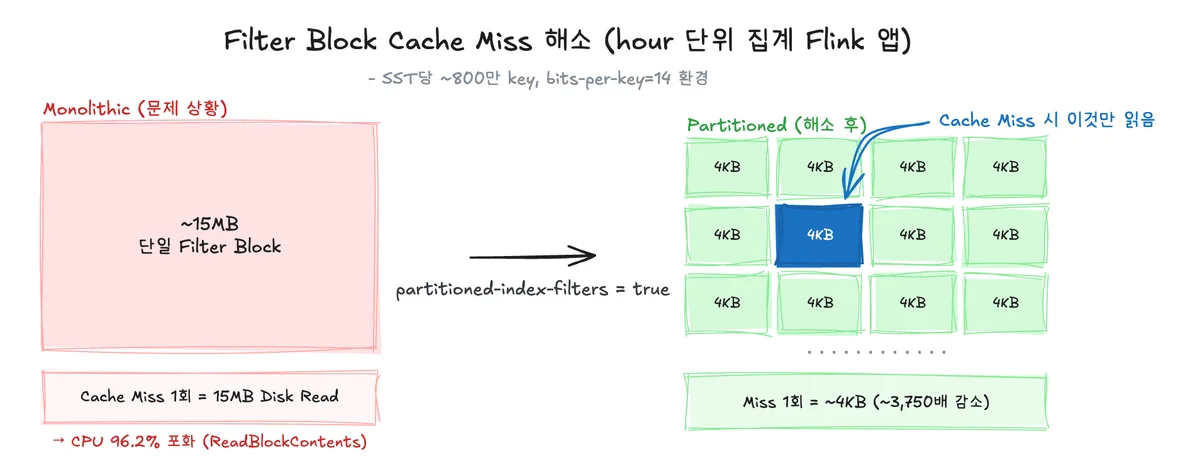
processElement와 onTimer 양쪽 경로 모두에서 ReadBlockContents()가 CPU를 지배하고 있었어요. Filter Block Cache Miss 합계가 1,699 / 1,766 = 96.2%. RocksDB가 point lookup 할 때마다 약 15MB 규모의 FilterBlock을 매번 디스크에서 읽어오는 구조였던 거예요.
왜 이렇게 심각했냐면, Direct I/O 환경이었기 때문이에요. K8s에서 RocksDB 돌릴 때는 OS Page Cache와 Block Cache 이중 버퍼링을 막으려 Direct I/O를 켜요. 덕분에 Cache Miss 시엔 Page Cache의 도움 없이 반드시 디스크. target-file-size-base=256MB, bits-per-key=14 환경에서는 SST 파일당 약 800만 개의 key가 들어가고, key당 14bits의 Bloom Filter가 생성되니 monolithic Filter Block이 약 15MB. miss 한 번에 15MB read가 터지는 셈이었어요.
해결은 partitioned-index-filters=true. Filter Block을 ~4KB partition으로 쪼개서 miss당 read가 약 2,750배 줄었어요.
함정이 하나 있었어요. bloom-filter.bits-per-key=14를 함께 설정했는데 먹히질 않았어요. Flink 내부 메서드 overwriteFilterIfExist()(RocksDBResourceContainer.java:287-298)가 bits-per-key를 10으로 강제 덮어쓰는 거예요. Flink 1.20 제약이었고, 우회 방법이 없었어요. 설정 파일에 값이 있다고 반드시 적용되는 게 아니더라고요. (이건 소스 코드까지 따라가야 보이는 종류의 덫이에요.)
레벨 최적화도 얹었어요. target-file-size-base를 64MB → 256MB로 올려 SST 파일 수를 줄였고, max-size-level-base를 256MB → 1GB, use-dynamic-size=true를 함께 걸었어요. 비활성 임계값이 25.6MB → 100MB로 올라가면서 hours 4개 윈도우 모두 L5가 비활성화. 활성 레벨이 3→2단계로 줄었고, Write Amplification도 multiplier(10) × (활성 레벨 수 - 1)로 근사해서 20→10(50%↓) 효과를 봤어요.
Redis 쓰기의 O(N) CPU 병목은 남아 있어요. 근데 이건 의도적으로 남긴 거예요. 현재 STRING Key 구조(userId × timeWindow)는 State→Redis 1:1 매핑이라, 장애 시 State 기반 복구가 가능한 구조거든요. SSOT 원칙을 유지하기 위해 O(N) 쓰기 비용을 감수한 거고, 코드 레벨 최적화는 중기 과제.
days — 220GB Savepoint와 Changelog
days 앱은 규모 자체가 다른 동네였어요. live-sst-files-size 기준으로 1일 9GB, 3일 32GB, 7일 68GB. TM당 10GB 수준. Savepoint는 220~230GB에 달해요. 원본 대비 2~3배 큰 이유는 Incremental이 아니라 전체 SST 파일을 포함하고, RocksDB SST에 적용된 블록 압축이 Flink canonical format에선 유지되지 않기 때문.
이 규모에서 매 Checkpoint마다 전체 State를 Snapshot하면? Checkpoint 자체가 병목이에요. Incremental Checkpoint를 써도 한계가 남아요. Compaction이 발생하면 기존 SST가 병합돼 새 SST가 생기고, 이전 Checkpoint에서 참조되지 않은 신규 파일로 간주되어 전부 업로드. 데이터 변화가 없어도 Compaction 겹치는 Checkpoint에서 업로드량이 급증하는 Long-tail Latency가 터지는 거예요.

Flink Changelog(DSTL)는 이 문제를 근본에서 해결해요. 데이터베이스의 WAL(Write-Ahead Log)과 같은 개념. State 변경마다 변경분을 즉시 로깅해두면, Checkpoint 시점엔 마지막 이후 변경분만 업로드하면 돼요. Compaction이 아무리 돌아도 업로드량에 영향 없음. SST 단위가 아니라 키 단위 증분이니까요.
Checkpoint는 두 단계로 나뉘어요. DSTL upload는 동기, 밀리초~초 단위로 완료. Materialization은 비동기, 별도 주기(minutes=5분, hours·days=10분)마다 전체 State 스냅샷을 HDFS에 저장하고 이전 Changelog를 truncate. 일 단위 집계 앱은 Checkpoint 주기 2분, min-pause 30초, Materialization 주기 10분으로 갔어요. 이 구성으로 Incremental Checkpoint 크기 기준 약 70MB 수준을 유지하고 있어요.
Native Savepoint와 Changelog의 교착 — 누구의 버그도 아닌
초기엔 NATIVE Savepoint를 썼어요. RocksDB SST 파일을 직접 참조해 복구가 빠르거든요. 근데 Changelog와 함께 쓰면 Materialization이 영구 중단되는 교착이 발생했어요.
소스 코드를 따라가보니 이유가 나왔어요. NATIVE Savepoint가 트리거되면 ChangelogKeyedStateBackend.nativeSavepoint()가 호출되고, 이 시점에 materializedId가 N → N+1로 증가해요. 이 ID는 '다음 Materialization이 확인해야 할 번호'. 문제는 이 ID를 되돌릴 경로가 없다는 거예요. CheckpointCoordinator는 비동기 Savepoint에 대해 완료 통지를 보내지 않거든요. 이유도 명확한 설계예요. Savepoint 완료 시 Kafka Offset Commit 같은 외부 Side Effect가 발생하는 걸 방지하려는 것.
notifyCheckpointComplete가 호출되지 않으면 lastConfirmedMaterializationId가 N-1에 영구 고착. 이후 Materialization 시도마다 "이전 게 아직 확인 안 됨"으로 판단해서 skip. 그 사이 DSTL은 무한 누적. Job을 재시작해야만 해소되는 상태.
CANONICAL Savepoint는 이 문제가 없어요. savepoint() 메서드를 호출하는데 이건 하위 RocksDB Backend에 단순 위임이라 materializedId를 건드리지 않거든요. CANONICAL로 전환해서 풀었어요.
이 교착은 어느 쪽의 버그도 아니에요. nativeSavepoint()가 materializedId를 증가시키는 건 Savepoint를 Materialization 기준점으로 삼기 위한 설계고, CheckpointCoordinator가 비동기 Savepoint에서 notifyCheckpointComplete를 호출하지 않는 것도 외부 Side Effect 방지 목적. 각각은 올바른데, 두 설계가 결합되면 ID 갱신 경로가 구조적으로 차단되는 거예요. 공식 문서로는 절대 안 보이는 종류의 버그였어요.
튜닝은 지표 → 소스 코드 → 설정의 반복
공통으로 적용한 부분도 정리해둘게요. Direct I/O는 K8s에서 Page Cache 이중 버퍼링과 예측 불가능한 메모리 점유를 막기 위한 선택. setUseDirectReads와 setUseDirectIoForFlushAndCompaction을 함께 켜야 read·flush·compaction 모든 경로에서 우회가 돼요. 단점은 Cache Miss 시 반드시 디스크인데, Direct I/O 환경에서 대형 SST를 쓰면 partitioned-index-filters=true는 선택이 아니라 필수예요.
Kryo→POJO 전환은 예상 밖의 성과였어요. async-profiler itimer로 보니 Kryo 관련 연산이 전체 CPU의 약 20%. POJO로 바꾸자 12%로 떨어졌어요. Block Cache 수용량 2.2배 향상, Changelog I/O 60%↓, Checkpoint 크기 3%↓까지 덤으로. 처음엔 직렬화 방식을 별도로 고민 안 했는데, 프로파일링으로 드러난 병목이었어요.
State 키 구조도 단순화했어요. 초기엔 MapState<String, Map<String, Map<String, Any>>>였는데, keyBy(사용자 ID)로 파티셔닝하면 Flink가 RocksDB state key prefix에 사용자 ID를 자동 포함하거든요. 외부 키를 별도 저장할 필요가 없었어요. 지금은 MapState<String, AdsFrequencyStats>로 단순화. 중첩 구조 제거로 직렬화 부하도 함께 줄었고요.
TM 메모리 영역도 실사용량 기반으로 쪼였어요. network buffer가 실제로 64MB 수준에서 머무는 걸 확인하고 3.4GB → 618MB로, task heap은 6GB → 4GB로. 10 TM 기준 K8s limit 132.9GB 절약. 숫자만 놓고 보면 별게 아닌 것 같은데, 공유 노드 환경에선 이런 절약이 쌓여 전체 안정성을 만들어요.
마무리
Head·Mid·Tail 세 계층 합산이 Redis 단일 조회로. Airflow DAG는 75회/일 → 25회/일로. 서빙 시점 Redis 조회는 최대 4회 → 1회로. 복잡도를 줄이는 게 원래 목표였고, 수치로도 확인됐어요.
세 앱의 병목이 서로 달랐는데, 분리했기 때문에 각자 독립적으로 풀 수 있었어요. 재처리 시 집계가 틀리던 문제도 Event Time 전환으로 구조에서 제거. bloom-filter.bits-per-key 덮어쓰기, withIdleness와 Bounded Source의 상호작용, Native Savepoint와 Changelog의 교착 — 공식 문서만으론 절대 알 수 없는 동작들이었어요.
처음부터 이 모든 걸 알고 시작한 건 아니에요. 지표에서 이상을 보고, 소스 코드를 추적하고, 설정을 조정하는 과정을 반복하면서 Flink와 RocksDB를 깊이 이해하게 됐다는 게 이 프로젝트의 진짜 결과물일지도 몰라요.