토스가 StarRocks 한 클러스터에 워크로드를 어떻게 격리했나
토스 DOP 팀이 StarRocks를 도입한 이후 운영의 핵심 질문은 하나였어요. "누구의 쿼리를 먼저 보호할 것인가." 한 클러스터 위에 광고 서빙, 대출 심사, 대시보드, Kafka 적재가 다 같이 굴러가니까요.
이유진 엔지니어가 정리한 운영기는 그 답을 찾아간 과정이에요. cpu_weight로 시작해서 exclusive_cpu_cores로, 그리고 Docker cpuset과 borrowing 의존 체인까지. 한 줄 정리하면, "설정값 하나가 클러스터 성능을 좌우하는 환경에서 함정 피하는 법"이에요.
왜 StarRocks였는지
이중 경로 문제가 시작이었어요. 서비스 개발에선 Spark 배치 결과랑 MySQL 온라인 쿼리를 같은 기준으로 비교해야 했고, 모니터링은 Hadoop 데이터를 별도 MySQL로 옮겨 서빙했죠. 번거로움.
StarRocks가 그 둘을 합쳤습니다. MySQL 유사 SQL이라 옮기기도 쉽고, 대용량 분석과 서비스 조회를 한 엔진에서 처리할 수 있었거든요. 클러스터는 용도별로 나눴어요. 서비스용 24시간 평균 69 qps, 1주 평균 87 qps. 모니터링·배치형은 24시간 평균 20 qps에 더 무거운 배치성 작업이 합쳐져 있었습니다.
근데 결국 평균 QPS가 문제가 아니에요. 다양한 워크로드가 같은 시간대에 겹칠 때 누구를 먼저 보호하느냐. 그게 진짜 질문이었습니다.
cpu_weight: 비유는 패스트트랙
Resource Group은 BE와 CN의 컴퓨팅 리소스를 논리적으로 나누는 기능이에요. 워크로드 우선순위는 서비스 쿼리 > 서버 배치 > 대규모 적재·백필 > 모니터링·사용자 쿼리 툴 순으로 봤습니다. 서비스 쿼리는 SLA, 배치는 완료 시간, 적재는 클러스터 압박, 대시보드는 가장 낮게.
cpu_weight를 비유하면 놀이공원 패스트트랙이에요. 줄이 비어 있으면 패스트든 일반이든 바로 타거든요. weight가 의미를 갖는 건 줄이 길어질 때, 즉 CPU가 경합할 때입니다. 내부적으로는 Linux CFS에서 영감 받은 자체 스케줄러가 100ms 타임 슬라이스로 양보하면서 동작하고요.
```sql CREATE RESOURCE GROUP service_wg TO (user='service_app', query_type IN ('SELECT')) WITH ('cpu_weight' = '50', 'mem_limit' = '40%', 'concurrency_limit' = '30');
CREATE RESOURCE GROUP batch_wg TO (user='airflow_batch', query_type IN ('INSERT')) WITH ('cpu_weight' = '10', 'mem_limit' = '60%', 'concurrency_limit' = '10'); ```
운영 결론은 단순해요. 일반적인 멀티테넌트 환경에서는 cpu_weight만으로도 많은 문제가 완화된다. 배타적 보호가 정말 필요할 때만 exclusive_cpu_cores로 올린다.
exclusive_cpu_cores는 진짜 코어를 떼어 줘요
이게 단순 예약이 아니에요. pthread_setaffinity_np로 스레드를 코어에 바인딩하고, 전용 ThreadPool을 통째로 3벌 분리합니다. DriverExecutor(파이프라인 드라이버 실행), ScanExecutor(로컬 OLAP 테이블 스캔), ConnectorScanExecutor(External Catalog 스캔). 이 3개를 공유 풀과 별도로 복제해서 가지고, 워커 스레드들이 지정 코어에만 붙도록 affinity를 설정해요.
설정 범위는 (0, min_be_cpu_cores - 1]. 같은 그룹 안에서 cpu_weight와 동시에 쓸 수 없어요. 클러스터 내에서 두 방식이 공존하는 건 가능합니다. 실제로 토스도 일부 그룹만 exclusive로 빼고 나머지는 cpu_weight로 운영했고요.
토스쇼핑 사례: 두 번의 조정
토스쇼핑 클러스터에 실시간 서비스 조회 계정(shopping_service)과 헤비 배치 계정(commerce_batch)이 같이 있었어요. 두 번 조정해야 했습니다.
1단계는 cpu_weight 조정. commerce_batch의 무거운 쿼리가 길게 점유하면서 shopping_service까지 같이 밀렸거든요. shopping_service에 더 높은 weight를, commerce_batch는 낮은 우선순위로.
근데 그걸로 부족했어요. 분당 약 1,500건 서비스 요청이 들어오는 구간에서 commerce_batch 쪽 헤비 배치가 겹치면 응답 시간이 계속 튀었거든요. CPU 상대 우선순위만으로는 안정적으로 막기 어려웠습니다.
2단계가 exclusive_cpu_cores 적용이에요. shopping_service만 별도 그룹으로 분리하고 전용 코어 할당. 결과? "튀던 패턴이 사라졌다"고 글에 적혀 있어요. cpu_weight로 시작해서 안 풀리면 exclusive로, 점진적으로 강화하는 흐름이 핵심입니다.
Classifier는 사실 자주 함정에 빠져요
Classifier는 쿼리 속성으로 리소스 그룹을 매칭하는 규칙이에요. 그런데 가중치가 조건마다 크게 달라요. db 조건은 데이터베이스 1개당 +10. user/role은 +1, source_ip나 query_type도 1점대. db가 들어간 classifier와 다른 조건의 classifier가 동시에 매칭되면 db 쪽이 거의 항상 이긴다는 얘기예요.
그래서 db 기반 classifier는 영향 범위가 넓다는 걸 인지하고 써야 합니다. user 조건만 잡아둔 다른 그룹이 있어도, db 설정이 들어간 그룹으로 빨려 들어가요. 운영에서 안정적으로 쓸 수 있는 패턴은 user 또는 db 기반으로 명확히 정하는 것.
조건 조합으로 weight를 합산해 의도한 그룹에 안정적으로 붙이는 방법도 있어요. `user='X' AND query_type IN ('SELECT')`처럼요.
마지막 함정. Classifier 직접 관리 대상은 일반 쿼리, INSERT INTO, Broker Load까지(StarRocks 3.4 기준). Routine Load와 Stream Load는 직접 제어 안 됩니다. Kafka 입수 같은 워크로드를 격리하려면 INSERT INTO 배치나 Broker Load 기준으로 설계해야 해요.
mem_limit 합이 100% 넘을 수 있다는 걸 모르면
대부분이 여기서 헷갈려요. mem_limit은 각 그룹의 상한이지, 예약이 아니거든요. Group A(80%)와 Group B(70%)가 동시에 최대로 쓰면 합 150%. 메모리 경합 발생. 이때 초과 쿼리는 종료됩니다.
``` Memory of load_wg exceed limit. Used: 203518716712, Limit: 203517025320. Mem usage has exceed the limit of the resource group [load_wg] ```
v4.0의 mem_pool은 동일 풀을 지정한 그룹들이 메모리 제한을 공유하는 기능이에요. v3.4 운영 중인 토스는 못 쓰지만, 업그레이드하면 합계 수동 관리 부담은 줄어들 거고요.
big_query 옵션은 폭주 쿼리를 자동 킬해줘요. 주의점은 이 제한이 쿼리 전체 합계가 아니라 개별 BE 노드 기준이라는 거. 10개 BE에 분산 실행되는 쿼리는 각 BE에서의 CPU time, scan rows, memory usage가 각각 limit과 비교됩니다.
Docker cpuset → bind_cpus → borrowing 체인
여기서부터가 실전이에요. 토스는 BE와 CN을 Docker 컨테이너로 배포해요. 이 구성이 Resource Group 동작에 영향을 주는데, 체인을 정확히 알아야 합니다.
``` Docker --cpuset-cpus 설정 │ └─→ enable_resource_group_bind_cpus = true │ ├─→ exclusive_cpu_cores 코어 바인딩 동작 │ └─→ enable_resource_group_cpu_borrowing 동작 가능 ```
상위 설정이 빠지면 하위가 무시됩니다.
주의점 1. Docker에서 `--cpus`만 쓰면 안 돼요. CPU 사용량만 제한할 뿐 코어 집합은 고정 안 됩니다. `--cpuset-cpus="0-91" --cpus=92` 이렇게 써야 bind_cpus와 cpu_borrowing이 동작해요.
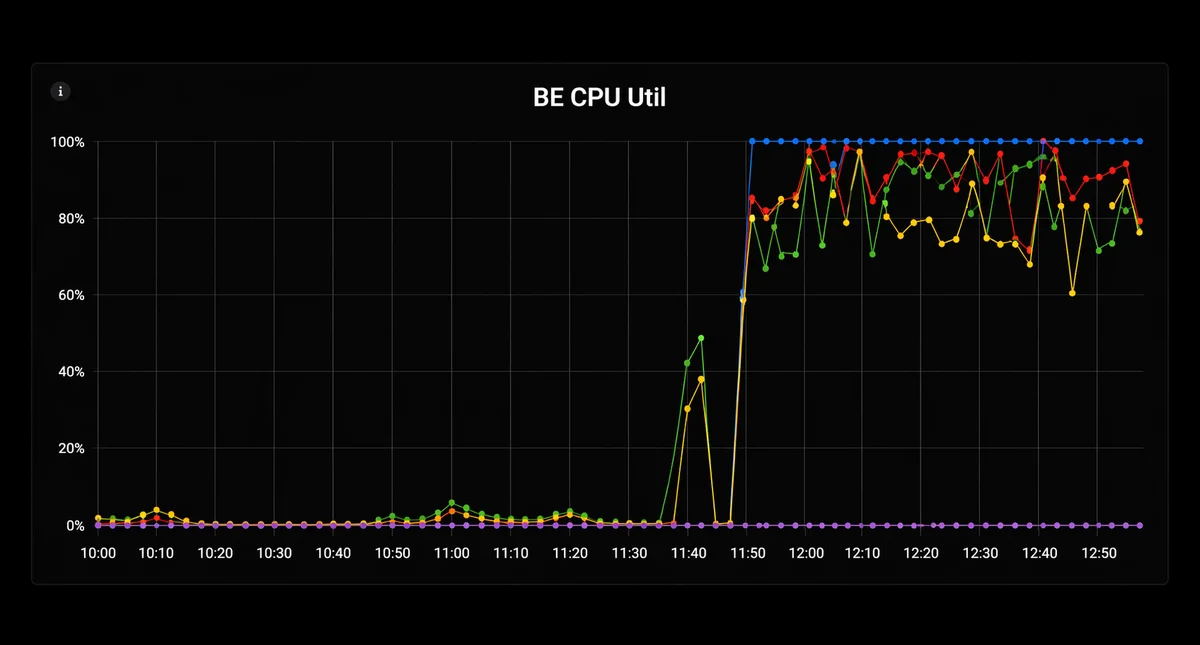
cpuset 미설정 상태에서도 exclusive_cpu_cores 자체는 동작은 해요. 92코어 BE에서 98%까지 점유하던 load_wg에 exclusive_cpu_cores=50을 설정했더니 CPU 부하는 60%로 제한됐는데, INSERT 쿼리 실행 시간이 약 380~457초로 약 100초 늘었어요. 트레이드오프죠. 다만 idle할 때 50개 코어가 놀게 되는데, borrowing으로 해결할 수 있어 보였습니다.
borrowing이 죽어 있던 이유
이게 함정. enable_resource_group_cpu_borrowing이 이미 true였는데, 다른 그룹이 idle 코어를 안 빌리고 있었어요. 다른 그룹 쿼리가 유휴 코어를 사용하면 CPU 사용량이 더 높아야 하는데 그렇지 않았거든요.
원인: enable_resource_group_bind_cpus가 false면 (기본값) borrowing도 자동 비활성화. 스레드가 물리 코어에 바인딩되어야 "이 코어가 놀고 있으니 빌려줄 수 있다"는 판단이 가능하니까요. Docker/cpuset 환경에서는 bind_cpus=false 상태에서 borrowing이 기대대로 동작하지 않아요. StarRocks GitHub Issue #49965에 정리되어 있는 의존 관계입니다.
cpuset_cpus + bind_cpus=true 설정 후 한 노드에 먼저 적용했어요. default_wg에서 헤비 쿼리 실행. 해당 노드만 CPU가 거의 100%까지 사용되고 나머지 노드는 낮은 수준 유지. borrowing 정상 동작 확인.
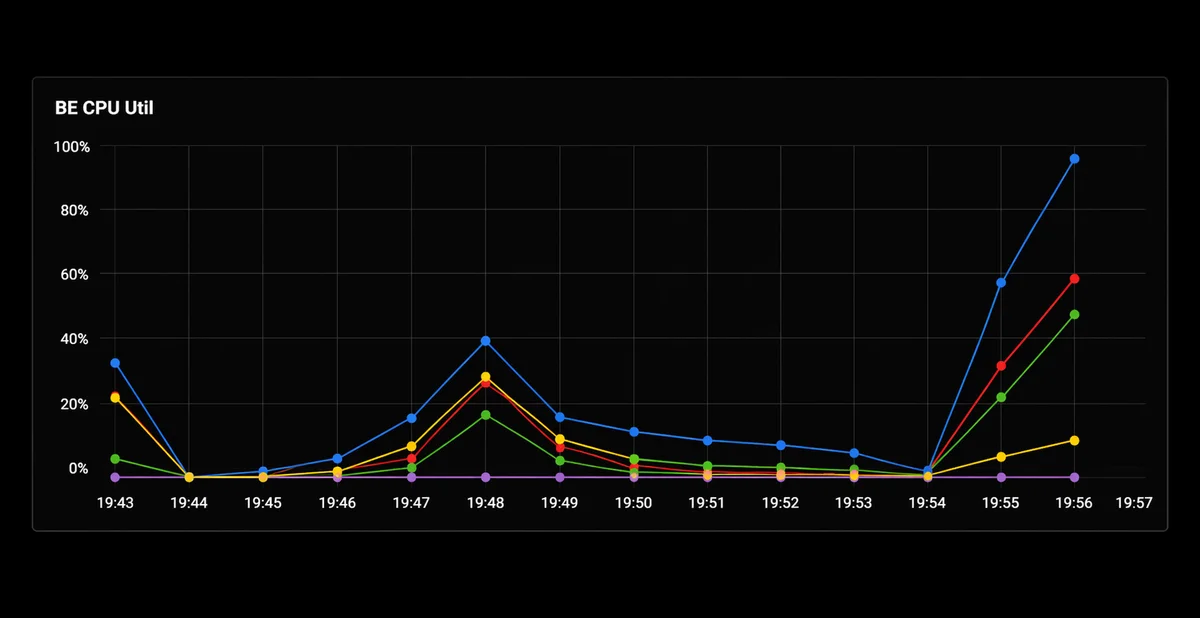
다만 borrowing=true에는 비용이 있어요. Exclusive 그룹에 쿼리가 다시 들어오면 yield 대기가 발생하는데, 일반 yield는 100ms인 반면 borrowed CPU에서 owner 쿼리가 존재하면 선제적 yield가 5ms로 짧아져요. p99 레이턴시가 5ms 미만인 서비스에는 borrowing=false를 권장합니다.
이종 스펙 노드의 함정
exclusive_cpu_cores 상한은 BE와 CN 합쳐서 최소 코어 수 - 1까지. 92코어 BE 10대와 16코어 CN 2대가 섞여 있으면 상한이 15(16-1). 92코어 기준 50으로 설정하려 했는데 CN 때문에 막히는 상황. 실제 운영에선 CN을 제외했다가 스펙 맞추고 다시 추가하는 식으로 우회했답니다.
클러스터에 이종 스펙 노드를 추가할 때 기존 Resource Group 설정이 깨질 수 있다는 점, 기억해 두세요.
모니터링 안 하면 잘 굴러가는지 모릅니다
Resource Group이 의도대로 동작하는지 확인하려면 쿼리 이력 모니터링이 필수예요. AuditLoader 플러그인이 모든 쿼리 실행 로그를 테이블에 적재하는데, resourceGroup, pendingTimeMs, queryTime, cpuCostNs 필드로 동작을 추적합니다.
pendingTimeMs > 0이면 큐 대기 발생 중. state = 'ERR'은 big_query 제한 등에 의해 킬된 쿼리. 그룹별로 나눠 보면 어디서 병목이 생기는지 보입니다.
```sql SELECT resourceGroup, DATE_TRUNC('hour', timestamp) AS hour, COUNT(*) AS query_count, AVG(pendingTimeMs) AS avg_pending_ms, MAX(pendingTimeMs) AS max_pending_ms, SUM(CASE WHEN state = 'ERR' THEN 1 ELSE 0 END) AS error_count FROM starrocks_audit_db__.starrocks_audit_tbl__ WHERE timestamp > DATE_SUB(NOW(), INTERVAL 24 HOUR) GROUP BY resourceGroup, hour; ```
토스는 한 발 더 나갔어요. 쿼리 이력을 StarRocks 내부 테이블에만 두면 클러스터 장애 시 모니터링도 같이 안 되니까, Kafka로 수집해서 외부 플랫폼에 이중 적재하고 Grafana 대시보드를 따로 구성했습니다. 클러스터가 죽어도 직전까지의 쿼리 로그는 추적 가능.
결국 cpu_weight면 충분한 경우가 대부분
운영하면서 계속 느꼈다고 적은 한 줄. cpu_weight만으로도 대부분의 멀티테넌트 문제가 완화된다는 거. exclusive_cpu_cores는 서비스 SLA처럼 하드 격리가 정말 필요할 때 꺼내는 카드.
그리고 한 가지 더. Resource Group은 중요한 쿼리를 보호하고 폭주 워크로드에 상한을 거는 도구지, 클러스터 용량을 늘려주는 기능이 아니에요. 워크로드 총량이 클러스터 용량에 근접하면 논리적 격리만으로는 한계가 있어요. CN 분리나 증설 같은 물리적 격리가 필요한 시점이 옵니다.
다음 글은 이 모든 게 실제로 동작하게 만드는 FE/BE/CN 서버 설정 — CPU 코어 수 하나로 60개 설정을 자동 계산하는 Ansible 템플릿 구조와, 설정을 잘못 복사해서 프로덕션이 멈춘 장애 사례. 운영자라면 그쪽이 더 무서울 거예요.