쿠팡·네이버·당근 19곳 robots.txt 까봤더니 — AI 봇 환영하는 곳, 40개 차단한 곳

한국 소비자 40% 이상이 상품 비교·발견 채널로 AI를 쓰고 있어요.
크리테오 '2026 커머스와 AI 트렌드 리포트' 숫자예요. 어센트AI 박세용 대표는 LLM 기반 AI 대화형 서비스로부터 웹사이트로의 평균 유입량이 8~10%까지 올라왔다고 말했고요. 검색 무게중심이 구글·네이버에서 챗GPT·클로드로 이동하는 동안, 이커머스 플랫폼들도 결정을 해야 했어요. AI 봇한테 문을 열 거냐, 닫을 거냐.
19곳이 적어둔, 다 다른 답
바이라인네트워크가 robots.txt로 쿠팡·네이버쇼핑 포함 국내 19개 이커머스 플랫폼의 AI 크롤링 허용 현황을 까봤어요. 결론 — 다 달랐어요.
robots.txt는 강제성이 없는 국제 지침이지만, 각 플랫폼이 정해둔 원칙이기도 해요. AI 크롤러를 어떻게 대하느냐에서 각 사 전략이 드러나는 거고요. 크게 두 갈래로 나뉘어요. 학습과 응답을 다 열어 AI를 신규 유입 채널로 끌어안는 '개방형', 양쪽 다 차단해 데이터를 지키는 '보호형'. 그리고 robots.txt에서 한 발 더 나아가 MCP(Model Context Protocol)까지 손대는 곳도 있고요.
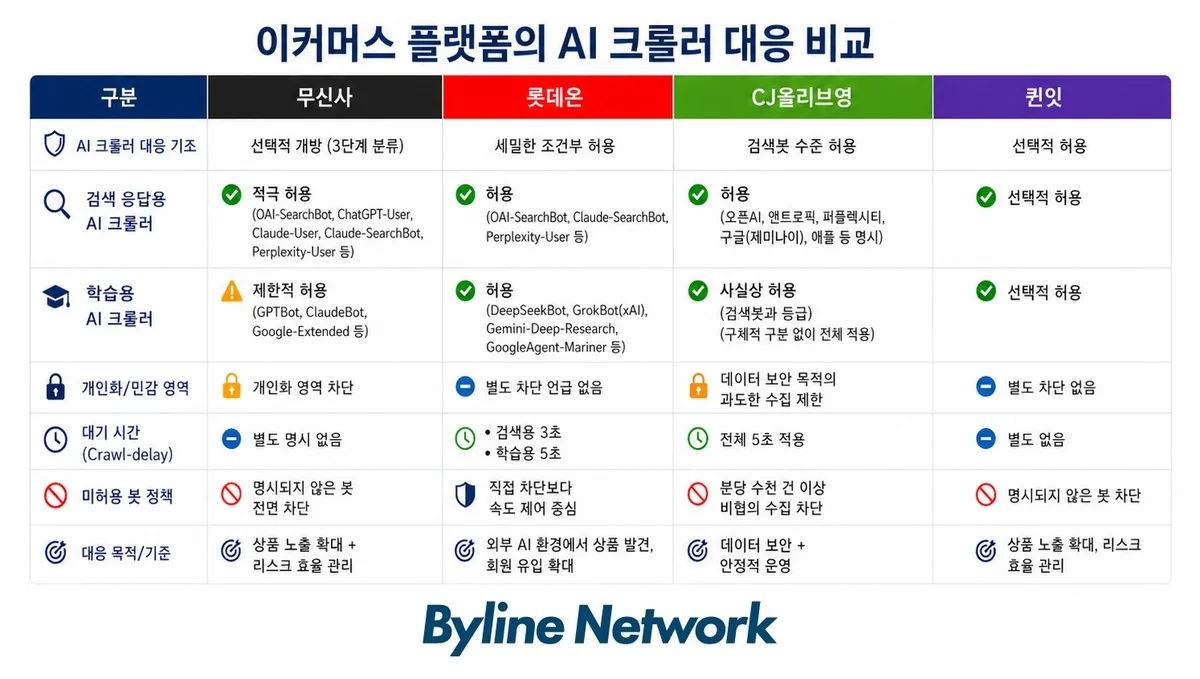
환영합니다, 단 시간차로 — 무신사·롯데온·CJ올리브영
무신사는 크롤러를 3단계로 분류했어요. AI 검색 응답용 크롤러(OpenAI의 OAI-SearchBot, ChatGPT-User, Anthropic의 Claude-User, Claude-SearchBot, Perplexity의 Perplexity-User)에는 문을 활짝 열었어요. AI 학습용 크롤러와 검색 엔진 크롤러(GPTBot, ClaudeBot, Google-Extended)는 개인화 영역만 차단했고요. 명시 안 된 나머지 봇? 전면 차단.
회사 측 입장은 이래요. "무신사 제품에 노출돼 좋은 관점에서는 노출하고, 리소스 등 여러 측면에서 도움이 되지 않는 건 허용하지 않는다." 노출과 비용 사이의 계산이 명확한 거예요.
롯데온은 한 층 더 세심해요. 최신 AI 생태계를 전면 반영해 robots.txt를 썼거든요. 단순히 열고 막는 게 아니라, 크롤러 요청 사이에 일정 시간을 강제했어요. AI 검색 응답용 크롤러는 대기 시간 3초, AI 학습용 크롤러(DeepSeekBot, GrokBot, Gemini-Deep-Research, GoogleAgent-Mariner)는 5초.
서버 과부하를 막으면서 자사 플랫폼에 유익한 방향으로 줄을 세운 거예요. 회사 측은 "롯데온으로 회원이 유입되고 롯데온에 있는 제품을 발견하는 채널로 보고 있다"고 답했어요. "외부 AI 환경에서도 상품 정보가 정확히 전달되도록 관리하고 있다"고요.
CJ올리브영은 AI 크롤러를 검색봇과 동급으로 허용하되 OpenAI·Anthropic·Perplexity·구글·애플을 명시적으로 나열했어요. 롯데온처럼 대기 시간 5초를 전체에 적용했고요. "데이터 보안과 온라인몰의 원활한 운영을 위해 분당 수천 건 이상의 협의되지 않은 정보 수집 시도는 막고 있다"는 게 회사 설명이에요.
40대 이상 여성 패션 플랫폼 퀸잇도 OpenAI와 Claude 등 AI 크롤러를 허용했어요. 이 연령대가 AI 검색·추천으로 이동하는 흐름을 의식한 결정이고요. 회사 측 표현이 인상적이에요. "트래픽을 얻을 수 있는 좋은 통로가 새로 열렸다는 판단 아래 GPT나 클로드를 통해 들어오는 순수 유입을 고려해 문을 여는 전략을 취하고 있다."
준비 단계인 곳도 있어요. 현대백화점의 프리미엄 큐레이션 플랫폼 더현대 하이는 AI 크롤러봇 일부에만 문을 열었어요. "오픈 초기 과도한 트래픽 부담을 줄이기 위해 일부 AI 크롤러만 허용했으며, 허용 범위를 단계적으로 넓혀갈 계획"이라는 입장. 출산·선물·생일 같은 주요 키워드를 상품명에 반영해서 AI 검색 결과에도 잡히도록 만들고 있고요.
꽁꽁 잠근 데이터 — 네이버·당근의 보호형
플랫폼 생태계를 이미 단단히 쥐고 있는 곳들은 정반대예요.
네이버플러스 스토어는 AI 크롤링과 RAG 목적의 접근을 아예 막아요. robots.txt에 'AI 크롤링 및 검색 증강 생성(RAG) 목적 접근 금지'를 직접 명시했고요. OpenAI와 Claude 등 AI 서비스 운영 기업의 크롤러를 하나하나 짚어 허용 안 한다고 기재했어요. 네이버 자체봇은 스토어와 브랜드 경로만 차단하고 나머지는 전면 허용했고요. 자기 데이터는 자기가 쓴다는 거예요.
당근은 더 나아갔어요. 40개 이상 봇을 개별 명시해서 사실상 전체를 차단했거든요. OpenAI, Claude뿐 아니라 AI 데이터 추출 전문 업체, 이미지 데이터셋 수집 도구까지요. 차단 리스트가 robots.txt가 아니라 거부 명단처럼 보일 정도예요.
두 회사 모두 자사 데이터 보호를 이유로 들었어요. 각 분야 점유율이 높고 여러 서비스로 플랫폼 내 생태계를 구축해온 곳들이라, 외부 AI를 통한 유입을 굳이 끌어들일 필요가 없는 거죠. 일종의 자기 충족적 결정이에요.
이 외에 서버 과부하를 막으려고 GPTBot을 초기에 차단한 곳도 있어요. 지그재그가 그 예시고요. 지마켓은 2023년경 GPTBot 허용을 명시해뒀는데 다른 봇들은 명시하지 않은 채 그대로 둬서, 어정쩡한 상태로 멈춰 있는 모양새예요.
같은 'AI 시대'를 다르게 본 두 갈래
흥미로운 건 두 진영의 논리가 정반대인데, 둘 다 자기 입장에서 합리적이라는 점이에요.
무신사·롯데온·CJ올리브영의 계산은 이거예요. AI 검색이 새로운 유입 통로니까, 우리 상품을 거기서 발견시켜야 한다. 단 우리 서버 부담은 통제한다. 그래서 대기 시간을 두고, 개인화 영역은 잠그고, 검색용/학습용을 구분해서 입장료를 다르게 받는 거죠. 일종의 '입국 심사'예요.
네이버·당근의 계산은 정반대예요. 우리 안에서 다 해결되는 사용자 동선을 갖고 있는데, 굳이 외부 AI한테 데이터를 내줄 이유가 없다. 외부 AI에 노출되는 건 우리 데이터를 무료로 빌려주는 거고, 그렇게 학습된 AI는 결국 우리 자리를 잠식할 수 있으니까요.
(어느 쪽이 맞을까요. 솔직히 카테고리에 따라 다를 거예요.)
탐색 빈도가 높고 가격 비교가 핵심인 카테고리에선 발견되는 게 우선이라 개방형이 유리해요. 반대로 사용자 락인이 강한 플랫폼은 잠가두는 게 단기적으론 합리적이고요. 다만 잠그고 버틸 수 있는 시간은 AI 검색의 소비자 채택 속도에 달려 있어요. 의무 단계가 오면, 늦게 문을 연 쪽은 비싼 입장료를 치르게 될 수도 있죠.
지금 19곳의 robots.txt는 그 시간차에 대한 19가지 베팅이에요.