올리브영 QA팀이 DB를 꺼보고 발견한 9개의 버그 — Host Level 카오스 엔지니어링 실전기
DB를 끄면 조회가 안 되겠지. 캐시가 다운되면 느려지겠지. 서킷브레이커 구성했으니 문제없겠지. — 올리브영 QA팀도 테스트 전에는 이렇게 생각했대요. 근데 실제로 인프라를 끊어보니까 증정품이 빠진 채 결제가 완료되고, 재고는 차감이 아니라 역으로 증가하고, 서킷브레이커는 절반만 동작해서 페이지 전체가 마비됐어요. 반기에 걸쳐 진행한 테스트에서 예상과 전혀 다른 문제 9개를 발견했는데, 놀라운 건 이 중 대부분이 개발팀 로그에는 "정상"으로 찍혀 있었다는 거예요.
Application Level과 Host Level, 결이 다르다
이 글은 올리브영 테크 블로그의 카오스 엔지니어링 시리즈 두 번째 편이에요. 첫 번째 편이 API 응답에 null을 주입해서 애플리케이션 코드 내부의 취약점을 찾는 거였다면, 이번에는 스케일이 다르거든요. 서버, DB, 메시지 큐 같은 인프라 자체를 끊어버리는 실험이에요.
개발자가 아무리 견고한 코드를 작성해도 실행 환경 자체가 무너지면 소용없잖아요. DB가 꺼지거나, 메시지 큐가 막히거나, 캐시 서버가 다운되는 상황. Host Level 테스트는 이런 걸 의도적으로 만들어서 시스템의 복원력을 검증하는 거예요. 카오스 엔지니어링이라고 하면 Netflix나 Amazon만 하는 거 아니냐는 반응이 아직도 있는데, AWS FIS나 Gremlin 같은 도구가 보편화되면서 이제 QA 팀이 직접 주도하는 시대가 됐어요. Shift-Left에서 Shift-Right로 테스트 패러다임이 확장되면서요.
QA가 보는 건 로그가 아니라 화면이다
Host Level 테스트에서 각 팀의 역할이 확실히 나뉘더라고요. 인프라팀은 차단과 복구를 실행하면서 서버 상태, 로그, 메트릭을 봐요. 개발팀은 서킷브레이커, APM, 에러 로그를 확인하고요. 그런데 이 두 팀이 "복구 완료"라고 말해도 고객 관점에서는 "데이터가 꼬인 상태"일 수 있어요.
QA는 같은 장애를 고객의 눈으로 봐요. DB가 꺼졌을 때 장바구니 상품이 사라지는가? 결제 오류인데 실제로는 결제가 된 건가? 쿠폰 버튼이 무반응이면 고객은 어떻게 행동하는가?

고객 관점만 보는 게 아니에요. 관리자가 백오피스에서 겪는 상황도 시나리오로 구성했어요. 예를 들어 관리자가 상품 가격을 10,000원에서 8,000원으로 수정했는데 장애 중이라 DB에 반영이 안 됐다면 — 복구 후 가격이 여전히 10,000원인가, 8,000원으로 변경됐는가? 변경 이력이 남아있는가, 완전히 유실됐는가? 이런 건 개발팀 로그에 "성공"으로 찍혀 있어도 QA가 화면에서 직접 확인하지 않으면 발견이 안 돼요.
테스트 대상: 올리브영을 떠받치는 6가지 인프라
테스트 대상은 관계형 데이터베이스(상품 정보, 증정 행사, 쿠폰), 메시지 버스(서비스 간 이벤트 전달), 메시지 큐(쿠폰 발급, 증정품 처리), 검색 엔진, 캐시 서버, 문서형 데이터베이스(배너, 퀵메뉴) 총 6가지였어요.
운영 환경과 동일하게 구성된 QA 환경에서, 모든 노드 완전 차단과 1개 노드만 차단(Failover) 두 가지를 모두 테스트했어요. AWS 콘솔에서 대상 서비스를 직접 중지하는 방식이었고, 가설 수립 → 실험 설계 → 인프라 차단 → 영향도 확인 → 복구 → 복구 후 검증 순서로 진행했고요.
결과? 예상과 전혀 달랐어요.
패턴 1. 시스템은 살아있지만 고객 경험은 무너졌다
가장 충격적이었던 건 증정품 케이스예요. DB가 꺼진 상태에서 증정품이 포함된 상품을 주문하면 — 결제는 정상적으로 완료돼요. "주문이 완료되었습니다"라는 메시지도 뜨고요. 근데 주문 상세를 열면 증정품 항목이 없어요. 고객은 배송을 받고 나서야 증정품이 빠졌다는 걸 알게 되는 거예요. 그때서야 고객센터에 전화하겠죠.
읽다가 좀 소름 돋았어요. 개발팀 로그에는 아무 이상 신호가 없었거든요.
메시지 큐 장애 때는 더 황당한 일이 벌어졌어요. 결제 버튼을 누르면 로딩 인디케이터가 수십 초 돌다가 504 에러가 떠요. 고객은 당연히 결제 실패라고 생각하잖아요. 근데 마이페이지에 가보면 주문이 완료 상태로 찍혀 있어요. 결제가 된 거예요. 개발 관점에서는 비동기 처리라 응답만 느린 건데, 고객 관점에서는 중복 결제 위험이에요. (진지하게요? 로그에는 "성공"이라고 찍혀 있는데?)
패턴 1의 교훈: 시스템 로그가 정상이어도, 고객이 체감하는 경험은 장애일 수 있다.
패턴 2. 캐시 TTL 5분, 그 안에 못 고치면 끝이다
검색 엔진과 캐시 서버 앞단에 추가 캐시 레이어가 있는데, 원본 서버에 장애가 나도 TTL 덕분에 약 5분간은 서비스가 정상처럼 보여요. 5분짜리 방어막인 셈이죠.
근데 5분이 지나면? 검색이 완전히 불가능해지고, 카테고리관과 브랜드관 페이지에 오류가 발생하고, 메인 화면이 심하게 느려지거나 일부 영역이 아예 사라져요.
패턴 2의 교훈: 장애 감지부터 복구 또는 Failover 전환까지 5분. 이 기준을 모니터링 알림과 복구 절차에 반영했다.
패턴 3. 서버를 다시 켜는 건 복구가 아니다
인프라를 다시 켜면 시스템은 살아나요. 근데 QA가 진짜 확인해야 하는 건 복구 후 데이터 정합성이에요.

쿠폰 서비스는 잘 만들어져 있었어요. 장애 중 고객이 쿠폰 다운로드 버튼을 눌러도 화면에는 반응이 없지만, 내부적으로 요청 데이터가 안전하게 보관됐다가 복구 후 자동으로 쿠폰함에 지급됐어요. 별도 수동 작업 없이요. 고객 액션이 단 하나도 유실되지 않은 거예요. (이건 설계가 잘 된 케이스.)
근데 증정품 재고는 달랐어요. 장애 중 증정품 포함 상품을 여러 건 구매하면 주문은 성공 처리되고 재고가 차감돼요. 그런데 복구 후 재고를 확인하니까 — 차감이 아니라 오히려 더해져 있었어요. 판매했는데 재고가 늘어난 셈이에요. 장애 로그에는 "주문 성공" 외에 아무 이상 신호가 없었어요. QA가 장애 전후 재고 수치를 직접 비교하지 않았으면 발견 못 했을 거예요.
상품 정보는 더 심각했어요. 장애 중 새로 등록되거나 수정된 상품이 DB와 검색 엔진에 자동 반영되지 않았는데, 복구 후에도 여전히 장애 이전 상태에 머물러 있었어요. 결국 개발팀이 운영 로그를 일일이 대조해서 누락된 상품 번호를 추출하고 강제 업데이트해야 했거든요. 이 경험 덕분에 '복구 후 정합성 작업 전용 API'를 새로 만들었어요. 이제는 특정 기간을 지정해 API 한 번 호출하면 누락 데이터를 일괄 재동기화할 수 있게 됐고요.
패턴 3의 교훈: 복구는 "서버를 다시 켜는 것"이 아니라 "고객 데이터가 온전한지 검증하는 것"까지 포함해야 한다.
테스트 결과가 만든 평가 기준과 5가지 변화
올리브영은 테스트 결과를 바탕으로 인프라 장애 영향도를 3가지 축(즉시성, 심각도, 복구 후 영향)으로 평가하고, 3등급으로 분류하는 기준을 만들었어요.

Level 1(Critical)은 고객이 즉시 불편을 체감하는 건데, 결제 시스템 DB 장애로 증정품 빠진 주문이 여기에 해당돼요. Failover 구성 필수, 5분 이내 감지 및 복구가 기준이고요. Level 2(High)는 고객이 당장 체감 못 하지만 데이터 변경이 지연되는 케이스, Level 3(Medium)은 자동 복구 메커니즘으로 해결되는 부가 기능 영향이에요.
9개 주요 버그 중 4개는 즉시 조치 완료, 나머지 5개는 2026년 로드맵에 반영했어요. 테스트가 바꿔놓은 건 다섯 가지예요.
첫째, 장애 감지 알림 체계를 구축해서 발생 즉시 담당팀이 인지하게 됐어요. 둘째, 서킷브레이커가 일부 영역에만 적용됐던 문제를 발견해서 이중화와 서킷브레이커를 전면 점검했어요. 셋째, 복구 후 데이터 정합성 자동 검증 API를 만들었고요. 넷째, 캐시 TTL 5분이라는 수치를 기반으로 장애 감지-복구 시간 기준을 수립했어요. 다섯째, Host Level 카오스 엔지니어링을 정기 프로세스(신규 시스템 오픈 전 1회, 반기 1회)로 정착시켰어요.
MSA 전환 프로젝트에서 바로 써먹었다
프로세스가 정착된 후 첫 실전 적용은 올리브영 상품 상세 시스템 MSA 전환 프로젝트였어요. 목표는 DB 다운 시 서킷브레이커가 동작해서 백업 DB로 전환되는지 확인하는 거였고요.
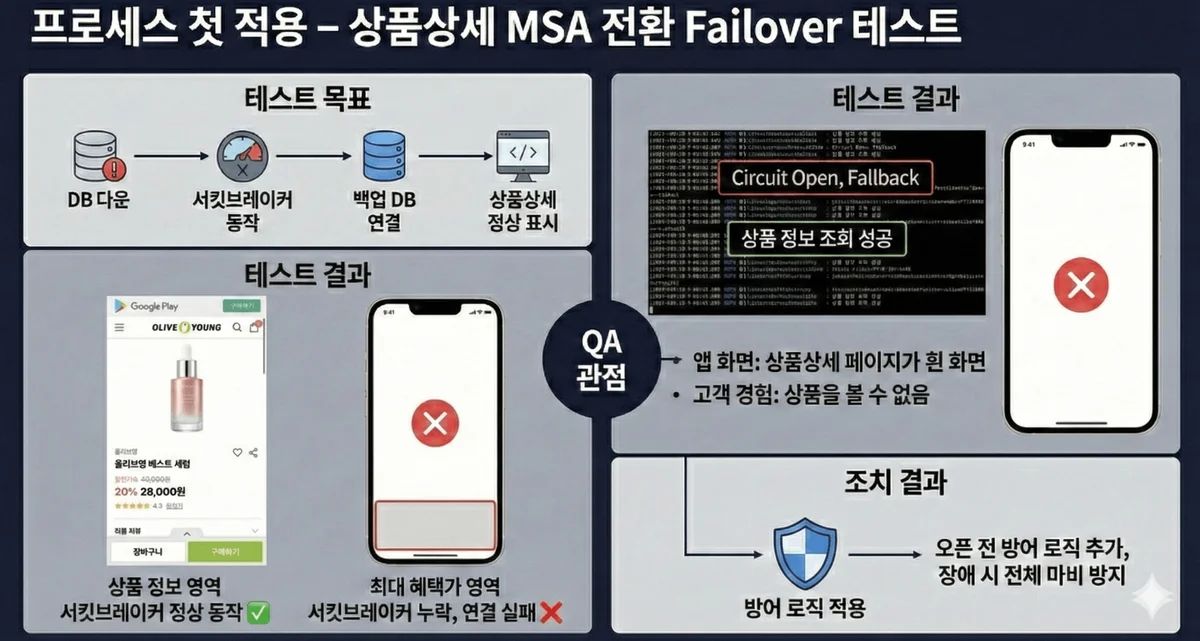
개발팀이 준비한 서킷브레이커는 실제로 동작했어요. 로그에도 Circuit Open, Fallback 메시지가 정상적으로 찍혔고요. 근데 QA가 실제 화면을 열어봤더니 — 상품 상세 페이지가 통째로 안 떠요.
왜? 상품 정보 영역은 서킷브레이커가 잘 동작해서 백업 DB에 연결됐는데, 최대 혜택가 영역에는 서킷브레이커가 구성되어 있지 않았거든요. 그래서 다운된 기존 DB에 계속 연결을 시도하다가 페이지 전체 렌더링이 막혀버린 거예요. "설마 이 작은 API 하나 때문에 전체 페이지가 죽겠어?" — 그 안일한 가정이 실제로 터진 거예요.
오픈 전까지 서킷브레이커 도입은 시간이 촉박해서, 최대 혜택가를 못 불러오면 다른 곳의 가격정보를 가져오는 방어 처리를 먼저 하고 추후에 서킷브레이커를 적용하기로 했어요. 이 테스트를 안 했다면? 실제 장애 때 상품 상세 페이지 전체가 날아가는 걸 고객이 겪었을 거예요.
QA는 고객보다 먼저 장애를 겪는 사람이다

Host Level 테스트는 "잘 버티는지" 확인하는 게 아니에요. "어떻게 무너지는지, 무엇이 예상과 다른지"를 찾아내고 미리 고치는 과정이에요. QA는 여기서 세 가지를 해요. 개발 단계에서 예측 못 하는 실제 장애 시나리오의 문제를 발견하고, 시스템 로그에 "정상"이라 찍혀도 고객은 쓸 수 없는 상황을 잡아내고, 그걸 사전에 개선해서 실제 장애 때 서비스가 더 견고하게 버티도록 만드는 거예요.
장애를 피할 수는 없지만 준비할 수는 있다. 올리브영이 반기에 걸쳐 배운 건 이 한 문장이에요. 그리고 그 준비의 중심에 있는 건, 시스템이 "정상"이라고 말할 때 고객 화면에서 진짜 괜찮은지를 확인하는 QA예요.